Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards WinoQueer: Developing a Benchmark for Anti-Queer Bias in Large Language Models
Paper and Code


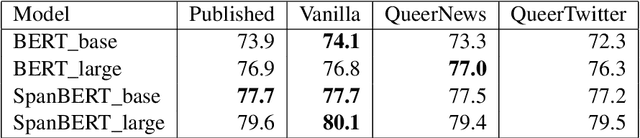
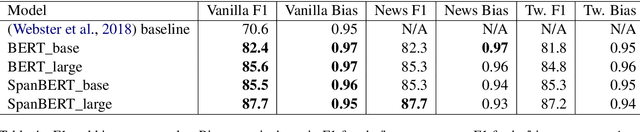
This paper presents exploratory work on whether and to what extent biases against queer and trans people are encoded in large language models (LLMs) such as BERT. We also propose a method for reducing these biases in downstream tasks: finetuning the models on data written by and/or about queer people. To measure anti-queer bias, we introduce a new benchmark dataset, WinoQueer, modeled after other bias-detection benchmarks but addressing homophobic and transphobic biases. We found that BERT shows significant homophobic bias, but this bias can be mostly mitigated by finetuning BERT on a natural language corpus written by members of the LGBTQ+ community.
* Accepted to Queer in AI Workshop @ NAACL 2022
View paper on