Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Large-Scale Discourse Structures in Pre-Trained and Fine-Tuned Language Models
Paper and Code
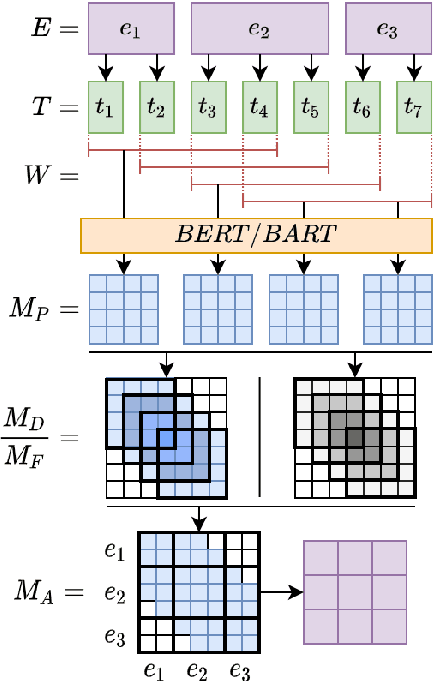
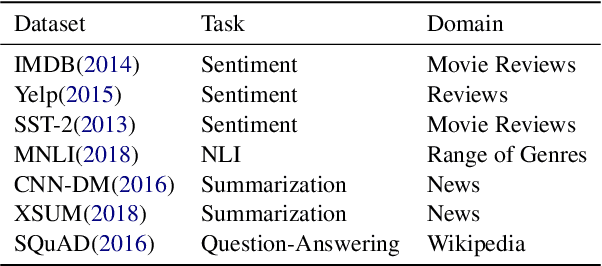
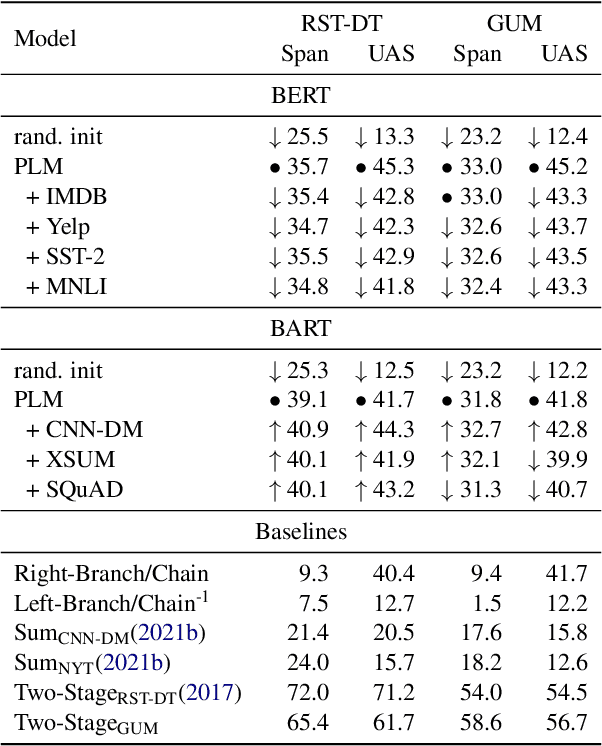
With a growing number of BERTology work analyzing different components of pre-trained language models, we extend this line of research through an in-depth analysis of discourse information in pre-trained and fine-tuned language models. We move beyond prior work along three dimensions: First, we describe a novel approach to infer discourse structures from arbitrarily long documents. Second, we propose a new type of analysis to explore where and how accurately intrinsic discourse is captured in the BERT and BART models. Finally, we assess how similar the generated structures are to a variety of baselines as well as their distribution within and between models.
* In Proceedings of the 2022 Conference of the North American
Chapter of the Association for Computational Linguistics (NAACL) * 9 pages
View paper on