 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning
Paper and Code

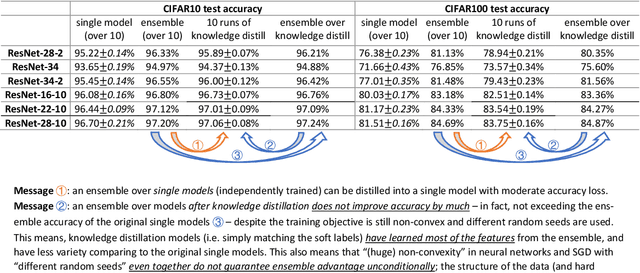


We formally study how Ensemble of deep learning models can improve test accuracy, and how the superior performance of ensemble can be distilled into a single model using Knowledge Distillation. We consider the challenging case where the ensemble is simply an average of the outputs of a few independently trained neural networks with the SAME architecture, trained using the SAME algorithm on the SAME data set, and they only differ by the random seeds used in the initialization. We empirically show that ensemble/knowledge distillation in deep learning works very differently from traditional learning theory, especially differently from ensemble of random feature mappings or the neural-tangent-kernel feature mappings, and is potentially out of the scope of existing theorems. Thus, to properly understand ensemble and knowledge distillation in deep learning, we develop a theory showing that when data has a structure we refer to as "multi-view", then ensemble of independently trained neural networks can provably improve test accuracy, and such superior test accuracy can also be provably distilled into a single model by training a single model to match the output of the ensemble instead of the true label. Our result sheds light on how ensemble works in deep learning in a way that is completely different from traditional theorems, and how the "dark knowledge" is hidden in the outputs of the ensemble -- that can be used in knowledge distillation -- comparing to the true data labels. In the end, we prove that self-distillation can also be viewed as implicitly combining ensemble and knowledge distillation to improve test accuracy.