Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Text-based Phishing Detection
Paper and Code
Nov 03, 2021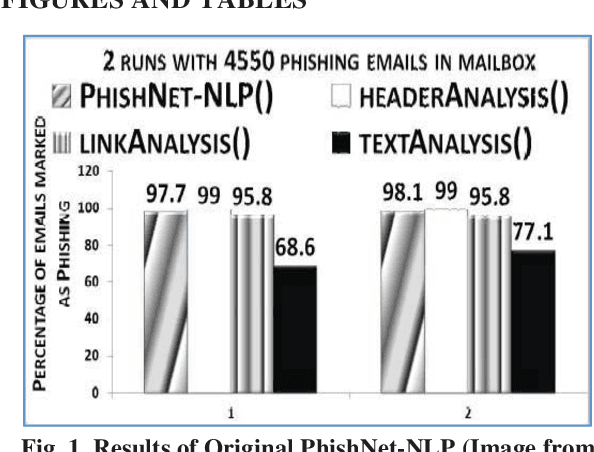
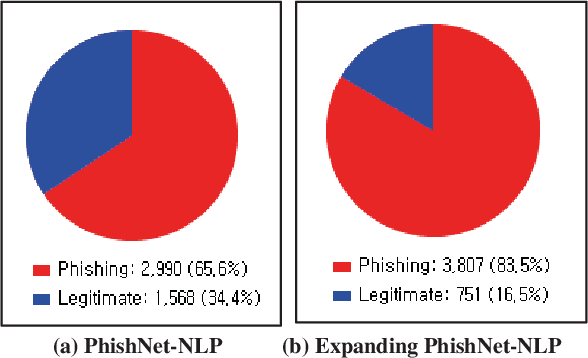
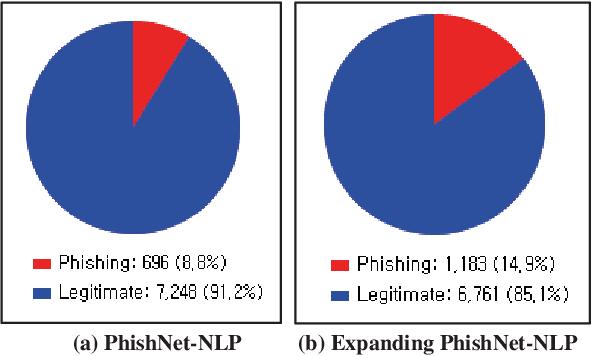
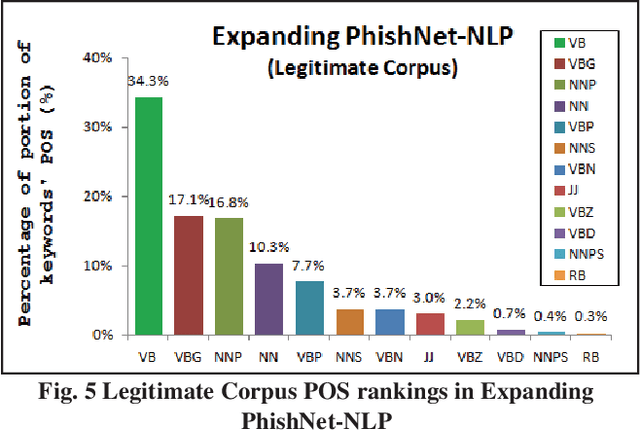
This paper reports on an experiment into text-based phishing detection using readily available resources and without the use of semantics. The developed algorithm is a modified version of previously published work that works with the same tools. The results obtained in recognizing phishing emails are considerably better than the previously reported work; but the rate of text falsely identified as phishing is slightly worse. It is expected that adding semantic component will reduce the false positive rate while preserving the detection accuracy.
* Society for Design and Process Science (SDPS) 2013, pp.187-192.
https://www.sdpsnet.org/sdps/documents/sdps-2013/SDPS_2013_proceedings.pdf
View paper on