Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Standard Criteria for human evaluation of Chatbots: A Survey
Paper and Code
May 24, 2021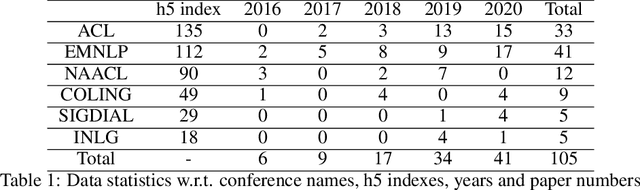

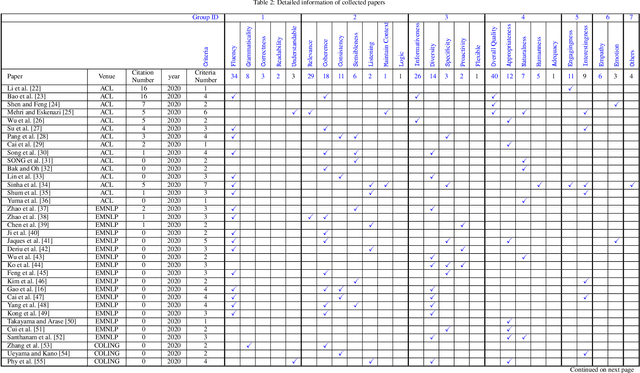

Human evaluation is becoming a necessity to test the performance of Chatbots. However, off-the-shelf settings suffer the severe reliability and replication issues partly because of the extremely high diversity of criteria. It is high time to come up with standard criteria and exact definitions. To this end, we conduct a through investigation of 105 papers involving human evaluation for Chatbots. Deriving from this, we propose five standard criteria along with precise definitions.
View paper on