 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safe Reinforcement Learning with a Safety Editor Policy
Paper and Code
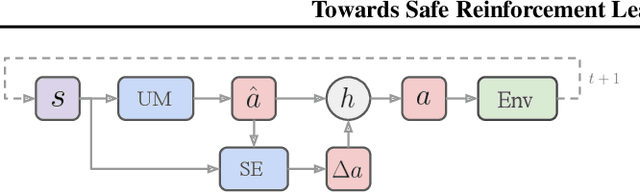
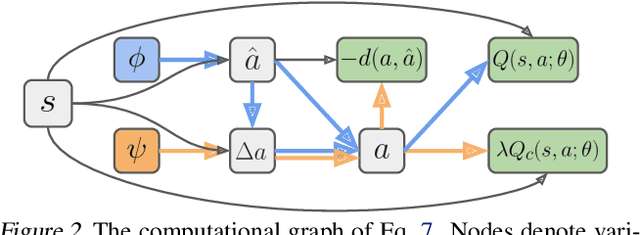

We consider the safe reinforcement learning (RL) problem of maximizing utility while satisfying provided constraints. Since we do not assume any prior knowledge or pre-training of the safety concept, we are interested in asymptotic constraint satisfaction. A popular approach in this line of research is to combine the Lagrangian method with a model-free RL algorithm to adjust the weight of the constraint reward dynamically. It relies on a single policy to handle the conflict between utility and constraint rewards, which is often challenging. Inspired by the safety layer design (Dalal et al., 2018), we propose to separately learn a safety editor policy that transforms potentially unsafe actions output by a utility maximizer policy into safe ones. The safety editor is trained to maximize the constraint reward while minimizing a hinge loss of the utility Q values of actions before and after the edit. On 12 custom Safety Gym (Ray et al., 2019) tasks and 2 safe racing tasks with very harsh constraint thresholds, our approach demonstrates outstanding utility performance while complying with the constraints. Ablation studies reveal that our two-policy design is critical. Simply doubling the model capacity of typical single-policy approaches will not lead to comparable results. The Q hinge loss is also important in certain circumstances, and replacing it with the usual L2 distance could fail badly.