Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robustness to Label Noise in Text Classification via Noise Modeling
Paper and Code
Jan 27, 2021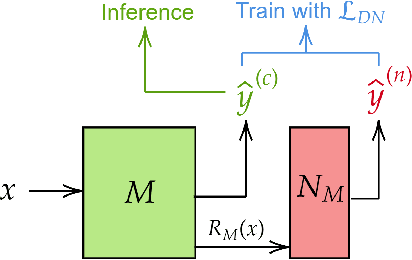

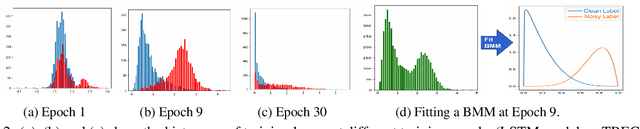

Large datasets in NLP suffer from noisy labels, due to erroneous automatic and human annotation procedures. We study the problem of text classification with label noise, and aim to capture this noise through an auxiliary noise model over the classifier. We first assign a probability score to each training sample of having a noisy label, through a beta mixture model fitted on the losses at an early epoch of training. Then, we use this score to selectively guide the learning of the noise model and classifier. Our empirical evaluation on two text classification tasks shows that our approach can improve over the baseline accuracy, and prevent over-fitting to the noise.
View paper on