 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Personalized Intelligence at Scale
Paper and Code
Mar 13, 2022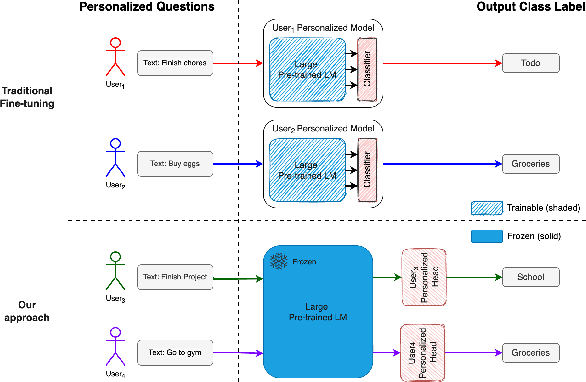

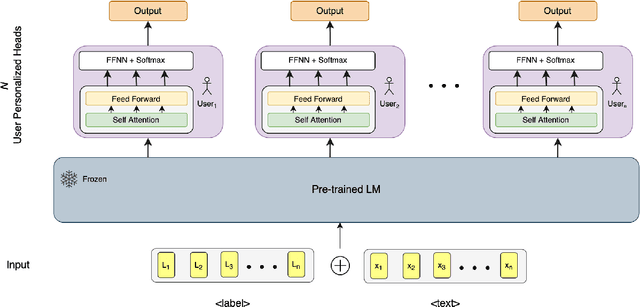
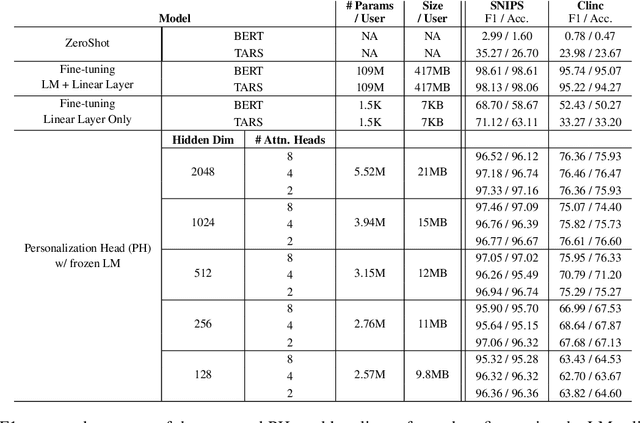
Personalized Intelligence (PI) is the problem of providing customized AI experiences tailored to each individual user. In many applications, PI is preferred or even required. Existing personalization approaches involve fine-tuning pre-trained models to create new customized models. However, these approaches require a significant amount of computation to train, scaling with model size and the number of users, inhibiting PI to be realized widely. In this work, we introduce a novel model architecture and training/inference framework to enable Personalized Intelligence at scale. We achieve this by attaching a Personalization Head (PH) to pre-trained language models (LM). During training, the base LMs are frozen and only the parameters in PH are updated and are unique per user. This results in significantly smaller overall model sizes and training cost than traditional fine-tuning approaches when scaled across many users. We evaluate PHs on academia and industry-focused datasets and show that the PHs outperform zeroshot baseline in F1 score and are significantly more scalable than traditional fine-tuning approaches. We identify key factors required for effective PH design and training.