 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards GAN Benchmarks Which Require Generalization
Paper and Code
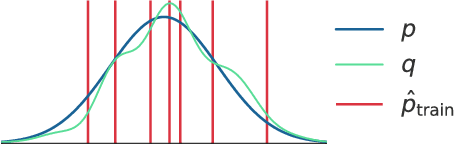
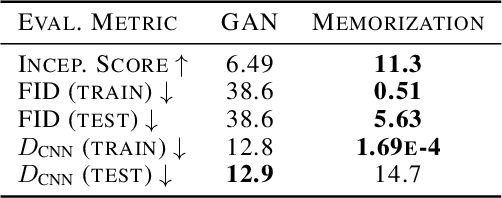

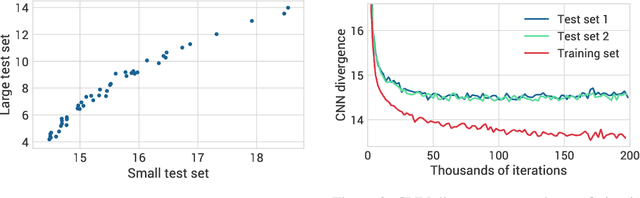
For many evaluation metrics commonly used as benchmarks for unconditional image generation, trivially memorizing the training set attains a better score than models which are considered state-of-the-art; we consider this problematic. We clarify a necessary condition for an evaluation metric not to behave this way: estimating the function must require a large sample from the model. In search of such a metric, we turn to neural network divergences (NNDs), which are defined in terms of a neural network trained to distinguish between distributions. The resulting benchmarks cannot be "won" by training set memorization, while still being perceptually correlated and computable only from samples. We survey past work on using NNDs for evaluation and implement an example black-box metric based on these ideas. Through experimental validation we show that it can effectively measure diversity, sample quality, and generalization.