 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainability in NLP: Analyzing and Calculating Word Saliency through Word Properties
Paper and Code
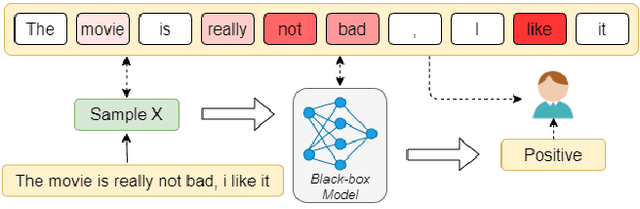
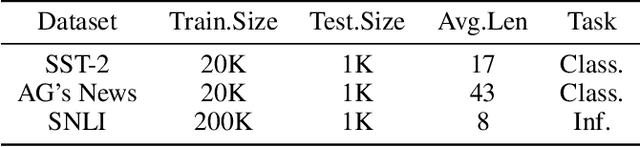

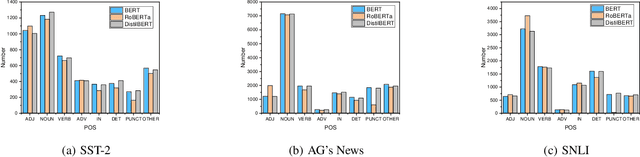
The wide use of black-box models in natural language processing brings great challenges to the understanding of the decision basis, the trustworthiness of the prediction results, and the improvement of the model performance. The words in text samples have properties that reflect their semantics and contextual information, such as the part of speech, the position, etc. These properties may have certain relationships with the word saliency, which is of great help for studying the explainability of the model predictions. In this paper, we explore the relationships between the word saliency and the word properties. According to the analysis results, we further establish a mapping model, Seq2Saliency, from the words in a text sample and their properties to the saliency values based on the idea of sequence tagging. In addition, we establish a new dataset called PrSalM, which contains each word in the text samples, the word properties, and the word saliency values. The experimental evaluations are conducted to analyze the saliency of words with different properties. The effectiveness of the Seq2Saliency model is verified.