Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards end-to-end F0 voice conversion based on Dual-GAN with convolutional wavelet kernels
Paper and Code
Apr 15, 2021
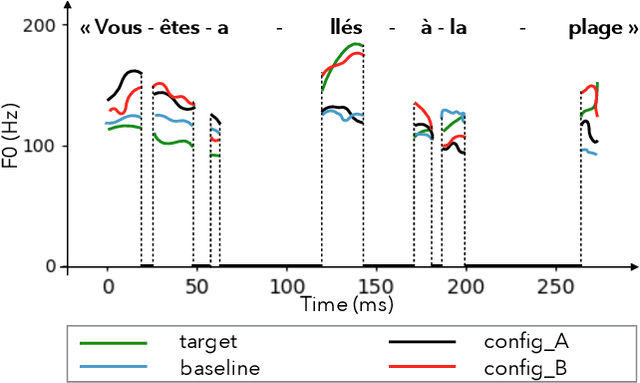
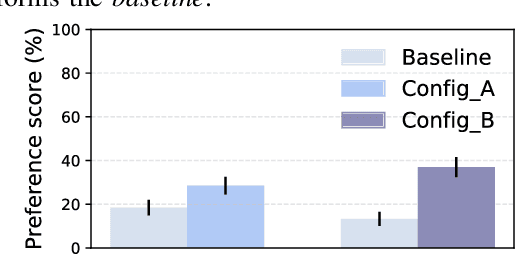
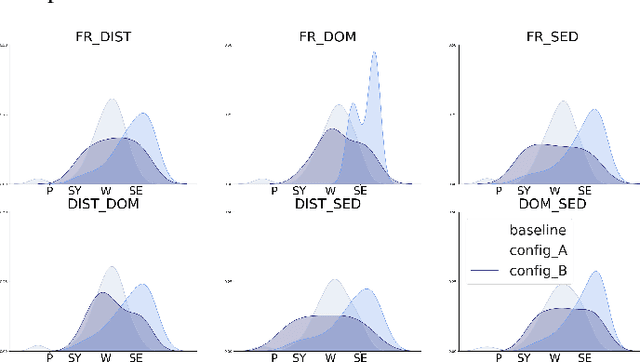
This paper presents a end-to-end framework for the F0 transformation in the context of expressive voice conversion. A single neural network is proposed, in which a first module is used to learn F0 representation over different temporal scales and a second adversarial module is used to learn the transformation from one emotion to another. The first module is composed of a convolution layer with wavelet kernels so that the various temporal scales of F0 variations can be efficiently encoded. The single decomposition/transformation network allows to learn in a end-to-end manner the F0 decomposition that are optimal with respect to the transformation, directly from the raw F0 signal.
View paper on