 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Dropout Training for Convolutional Neural Networks
Paper and Code
Dec 01, 2015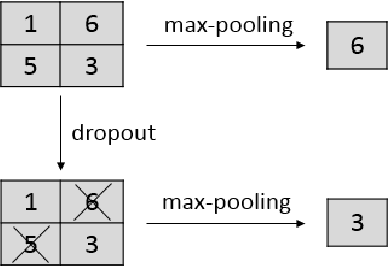
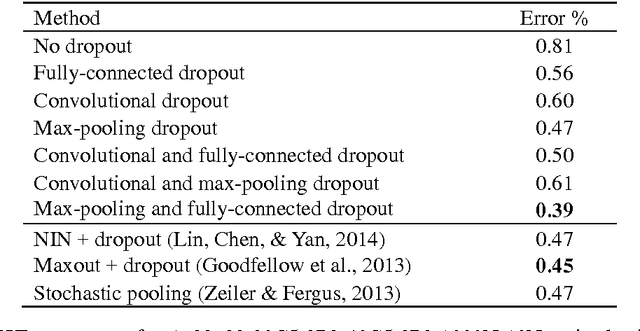


Recently, dropout has seen increasing use in deep learning. For deep convolutional neural networks, dropout is known to work well in fully-connected layers. However, its effect in convolutional and pooling layers is still not clear. This paper demonstrates that max-pooling dropout is equivalent to randomly picking activation based on a multinomial distribution at training time. In light of this insight, we advocate employing our proposed probabilistic weighted pooling, instead of commonly used max-pooling, to act as model averaging at test time. Empirical evidence validates the superiority of probabilistic weighted pooling. We also empirically show that the effect of convolutional dropout is not trivial, despite the dramatically reduced possibility of over-fitting due to the convolutional architecture. Elaborately designing dropout training simultaneously in max-pooling and fully-connected layers, we achieve state-of-the-art performance on MNIST, and very competitive results on CIFAR-10 and CIFAR-100, relative to other approaches without data augmentation. Finally, we compare max-pooling dropout and stochastic pooling, both of which introduce stochasticity based on multinomial distributions at pooling stage.