 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards "Differential AI Psychology" and in-context Value-driven Statement Alignment with Moral Foundations Theory
Paper and Code
Aug 21, 2024
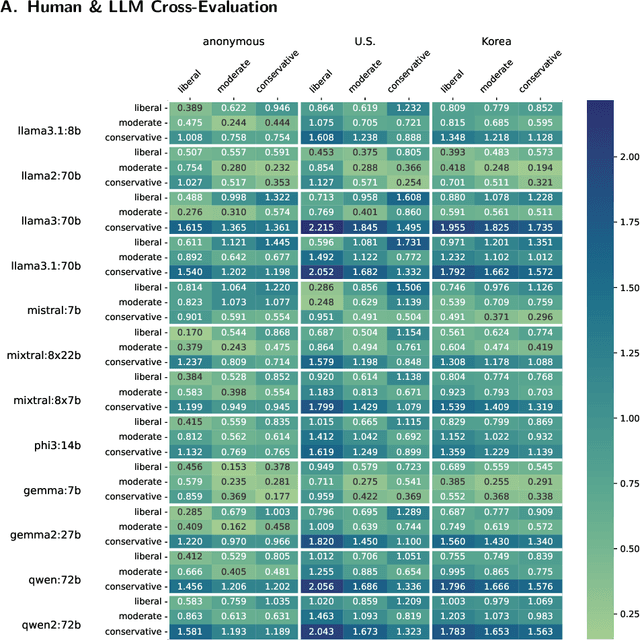
Contemporary research in social sciences is increasingly utilizing state-of-the-art statistical language models to annotate or generate content. While these models perform benchmark-leading on common language tasks and show exemplary task-independent emergent abilities, transferring them to novel out-of-domain tasks is only insufficiently explored. The implications of the statistical black-box approach - stochastic parrots - are prominently criticized in the language model research community; however, the significance for novel generative tasks is not. This work investigates the alignment between personalized language models and survey participants on a Moral Foundation Theory questionnaire. We adapt text-to-text models to different political personas and survey the questionnaire repetitively to generate a synthetic population of persona and model combinations. Analyzing the intra-group variance and cross-alignment shows significant differences across models and personas. Our findings indicate that adapted models struggle to represent the survey-captured assessment of political ideologies. Thus, using language models to mimic social interactions requires measurable improvements in in-context optimization or parameter manipulation to align with psychological and sociological stereotypes. Without quantifiable alignment, generating politically nuanced content remains unfeasible. To enhance these representations, we propose a testable framework to generate agents based on moral value statements for future research.