 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Design Space Exploration and Optimization of Fast Algorithms for Convolutional Neural Networks (CNNs) on FPGAs
Paper and Code
Mar 05, 2019
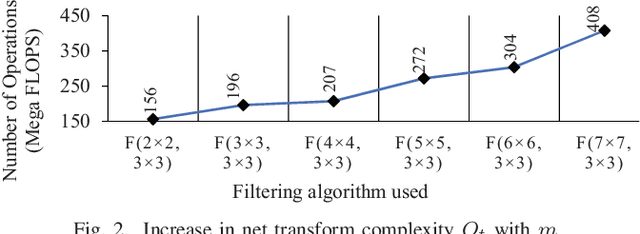
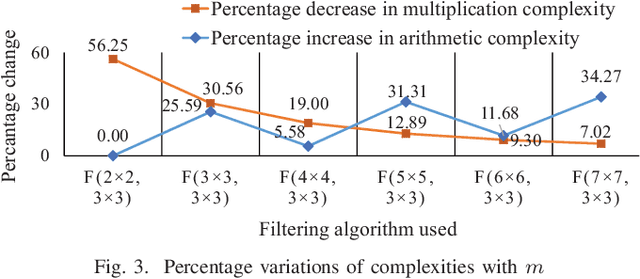
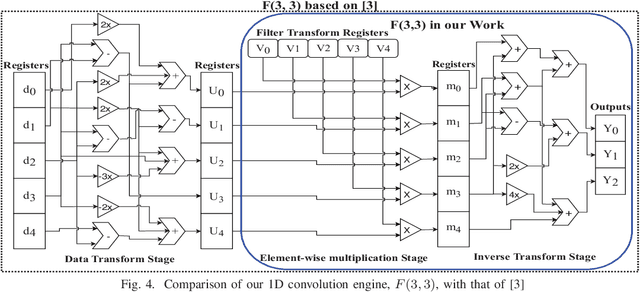
Convolutional Neural Networks (CNNs) have gained widespread popularity in the field of computer vision and image processing. Due to huge computational requirements of CNNs, dedicated hardware-based implementations are being explored to improve their performance. Hardware platforms such as Field Programmable Gate Arrays (FPGAs) are widely being used to design parallel architectures for this purpose. In this paper, we analyze Winograd minimal filtering or fast convolution algorithms to reduce the arithmetic complexity of convolutional layers of CNNs. We explore a complex design space to find the sets of parameters that result in improved throughput and power-efficiency. We also design a pipelined and parallel Winograd convolution engine that improves the throughput and power-efficiency while reducing the computational complexity of the overall system. Our proposed designs show up to 4.75$\times$ and 1.44$\times$ improvements in throughput and power-efficiency, respectively, in comparison to the state-of-the-art design while using approximately 2.67$\times$ more multipliers. Furthermore, we obtain savings of up to 53.6\% in logic resources compared with the state-of-the-art implementation.