 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Code-switched Classification Exploiting Constituent Language Resources
Paper and Code
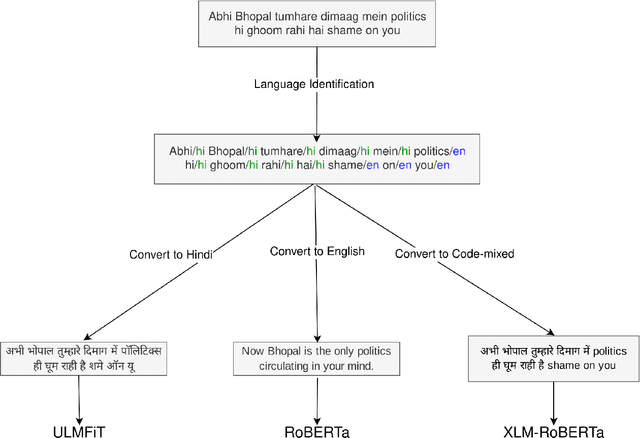


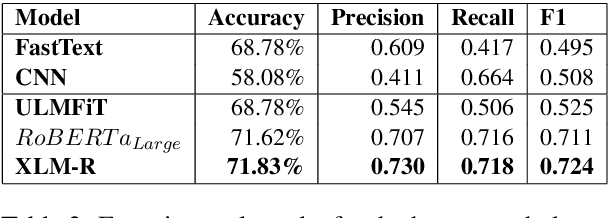
Code-switching is a commonly observed communicative phenomenon denoting a shift from one language to another within the same speech exchange. The analysis of code-switched data often becomes an assiduous task, owing to the limited availability of data. We propose converting code-switched data into its constituent high resource languages for exploiting both monolingual and cross-lingual settings in this work. This conversion allows us to utilize the higher resource availability for its constituent languages for multiple downstream tasks. We perform experiments for two downstream tasks, sarcasm detection and hate speech detection, in the English-Hindi code-switched setting. These experiments show an increase in 22% and 42.5% in F1-score for sarcasm detection and hate speech detection, respectively, compared to the state-of-the-art.