 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Psychotherapy via Language Modeling
Paper and Code
Apr 05, 2021

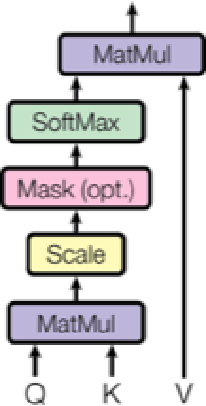

In this experiment, a model was devised, trained, and evaluated to automate psychotherapist/client text conversations through the use of state-of-the-art, Seq2Seq Transformer-based Natural Language Generation (NLG) systems. Through training the model upon a mix of the Cornell Movie Dialogue Corpus for language understanding and an open-source, anonymized, and public licensed psychotherapeutic dataset, the model achieved statistically significant performance in published, standardized qualitative benchmarks against human-written validation data - meeting or exceeding human-written responses' performance in 59.7% and 67.1% of the test set for two independent test methods respectively. Although the model cannot replace the work of psychotherapists entirely, its ability to synthesize human-appearing utterances for the majority of the test set serves as a promising step towards communizing and easing stigma at the psychotherapeutic point-of-care.