 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Diverse Text Generation with Inverse Reinforcement Learning
Paper and Code
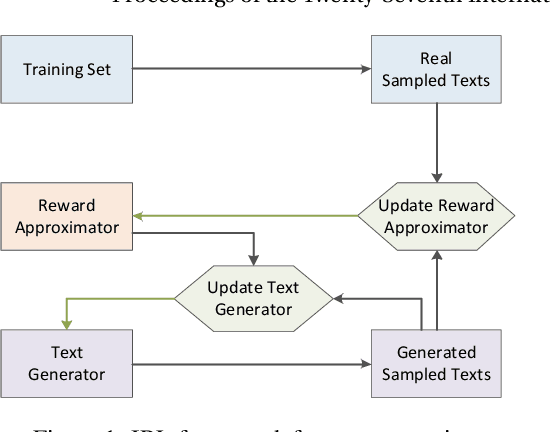
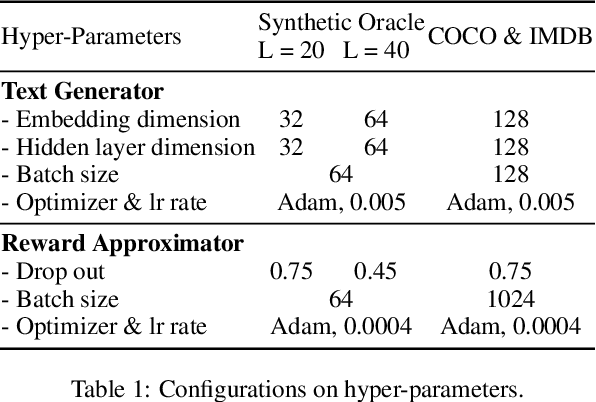
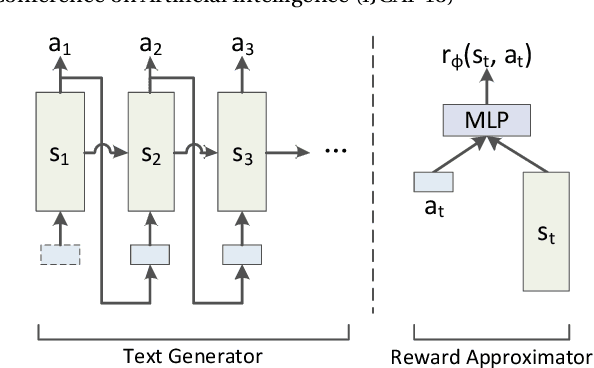

Text generation is a crucial task in NLP. Recently, several adversarial generative models have been proposed to improve the exposure bias problem in text generation. Though these models gain great success, they still suffer from the problems of reward sparsity and mode collapse. In order to address these two problems, in this paper, we employ inverse reinforcement learning (IRL) for text generation. Specifically, the IRL framework learns a reward function on training data, and then an optimal policy to maximum the expected total reward. Similar to the adversarial models, the reward and policy function in IRL are optimized alternately. Our method has two advantages: (1) the reward function can produce more dense reward signals. (2) the generation policy, trained by "entropy regularized" policy gradient, encourages to generate more diversified texts. Experiment results demonstrate that our proposed method can generate higher quality texts than the previous methods.