Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Standardized and More Accurate Indonesian Part-of-Speech Tagging
Paper and Code
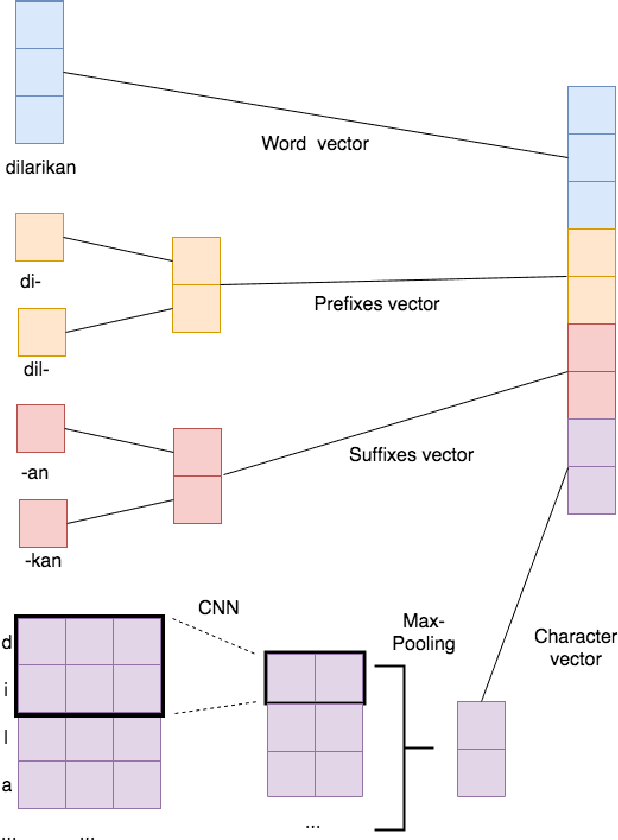
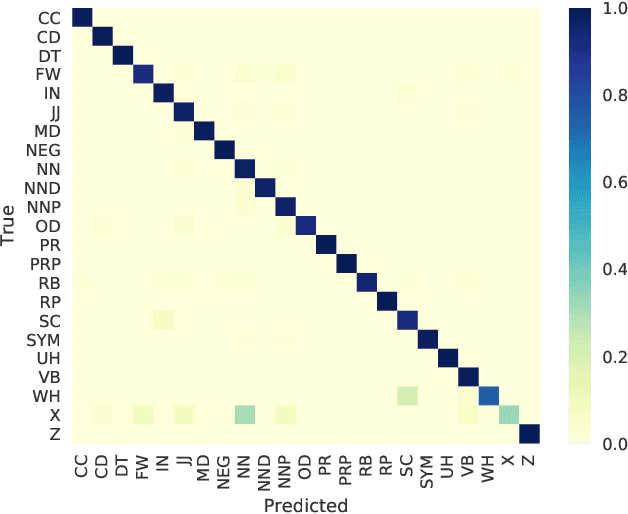
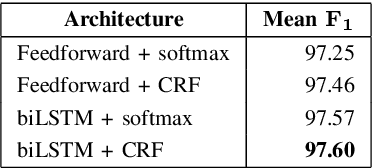
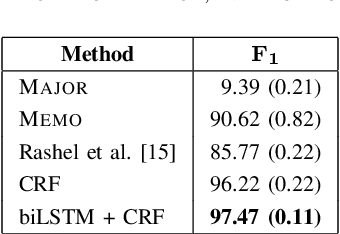
Previous work in Indonesian part-of-speech (POS) tagging are hard to compare as they are not evaluated on a common dataset. Furthermore, in spite of the success of neural network models for English POS tagging, they are rarely explored for Indonesian. In this paper, we explored various techniques for Indonesian POS tagging, including rule-based, CRF, and neural network-based models. We evaluated our models on the IDN Tagged Corpus. A new state-of-the-art of 97.47 F1 score is achieved with a recurrent neural network. To provide a standard for future work, we release the dataset split that we used publicly.
* Accepted in IALP 2018
View paper on