 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-K Off-Policy Correction for a REINFORCE Recommender System
Paper and Code
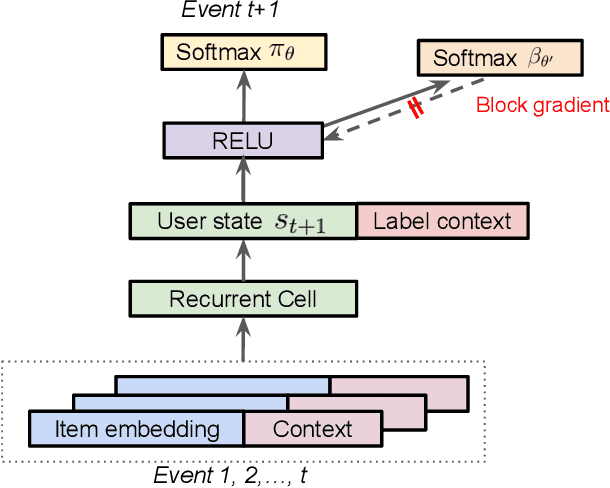
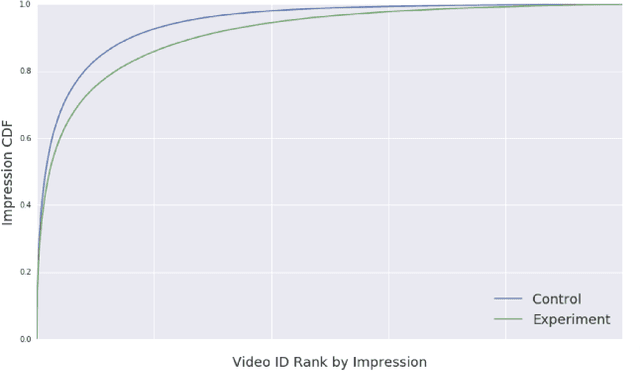
Industrial recommender systems deal with extremely large action spaces -- many millions of items to recommend. Moreover, they need to serve billions of users, who are unique at any point in time, making a complex user state space. Luckily, huge quantities of logged implicit feedback (e.g., user clicks, dwell time) are available for learning. Learning from the logged feedback is however subject to biases caused by only observing feedback on recommendations selected by the previous versions of the recommender. In this work, we present a general recipe of addressing such biases in a production top-K recommender system at Youtube, built with a policy-gradient-based algorithm, i.e. REINFORCE. The contributions of the paper are: (1) scaling REINFORCE to a production recommender system with an action space on the orders of millions; (2) applying off-policy correction to address data biases in learning from logged feedback collected from multiple behavior policies; (3) proposing a novel top-K off-policy correction to account for our policy recommending multiple items at a time; (4) showcasing the value of exploration. We demonstrate the efficacy of our approaches through a series of simulations and multiple live experiments on Youtube.