 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToo good to be true? Predicting author profiles from abusive language
Paper and Code
Sep 03, 2020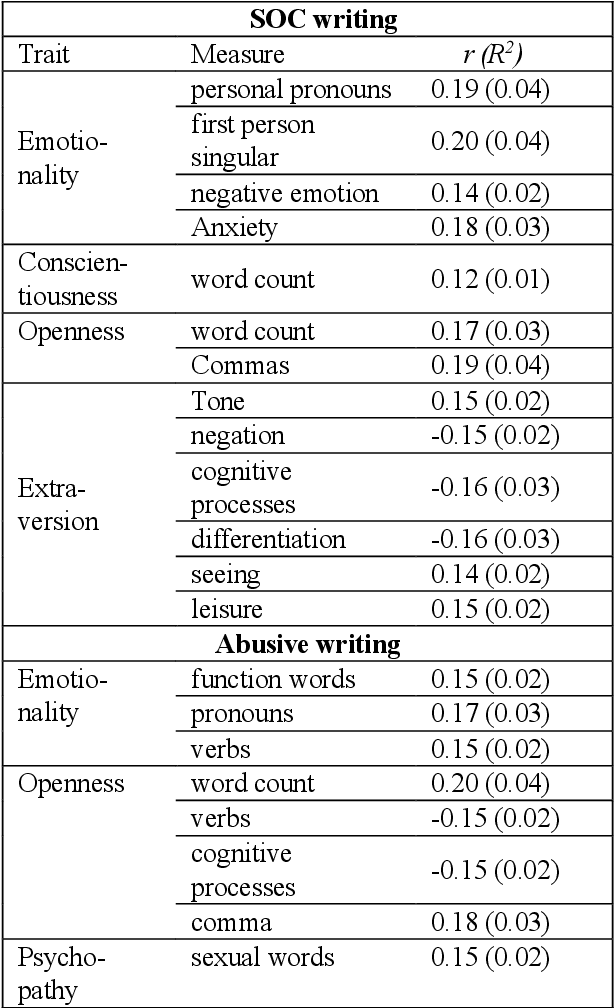
The problem of online threats and abuse could potentially be mitigated with a computational approach, where sources of abuse are better understood or identified through author profiling. However, abusive language constitutes a specific domain of language for which it has not yet been tested whether differences emerge based on a text author's personality, age, or gender. This study examines statistical relationships between author demographics and abusive vs normal language, and performs prediction experiments for personality, age, and gender. Although some statistical relationships were established between author characteristics and language use, these patterns did not translate to high prediction performance. Personality traits were predicted within 15% of their actual value, age was predicted with an error margin of 10 years, and gender was classified correctly in 70% of the cases. These results are poor when compared to previous research on author profiling, therefore we urge caution in applying this within the context of abusive language and threat assessment.