 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToeplitz Inverse Covariance based Robust Speaker Clustering for Naturalistic Audio Streams
Paper and Code
Jul 12, 2019
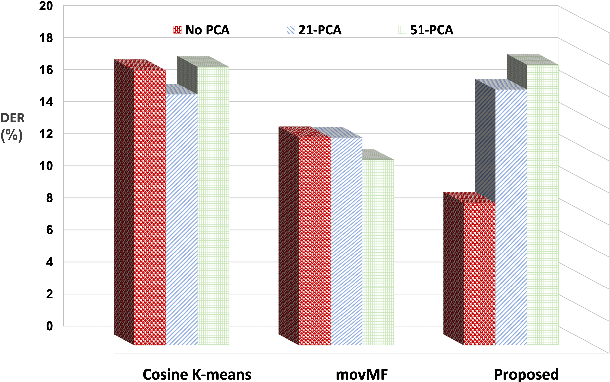
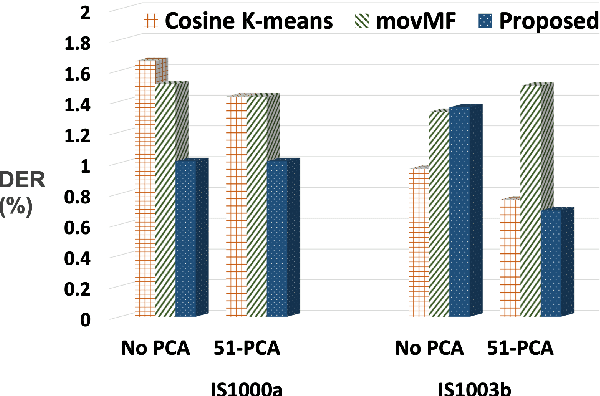
Speaker diarization determines who spoke and when? in an audio stream. In this study, we propose a model-based approach for robust speaker clustering using i-vectors. The ivectors extracted from different segments of same speaker are correlated. We model this correlation with a Markov Random Field (MRF) network. Leveraging the advancements in MRF modeling, we used Toeplitz Inverse Covariance (TIC) matrix to represent the MRF correlation network for each speaker. This approaches captures the sequential structure of i-vectors (or equivalent speaker turns) belonging to same speaker in an audio stream. A variant of standard Expectation Maximization (EM) algorithm is adopted for deriving closed-form solution using dynamic programming (DP) and the alternating direction method of multiplier (ADMM). Our diarization system has four steps: (1) ground-truth segmentation; (2) i-vector extraction; (3) post-processing (mean subtraction, principal component analysis, and length-normalization) ; and (4) proposed speaker clustering. We employ cosine K-means and movMF speaker clustering as baseline approaches. Our evaluation data is derived from: (i) CRSS-PLTL corpus, and (ii) two meetings subset of the AMI corpus. Relative reduction in diarization error rate (DER) for CRSS-PLTL corpus is 43.22% using the proposed advancements as compared to baseline. For AMI meetings IS1000a and IS1003b, relative DER reduction is 29.37% and 9.21%, respectively.