Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo impute or not to impute: How machine learning modelers treat missing data
Paper and Code
Mar 20, 2025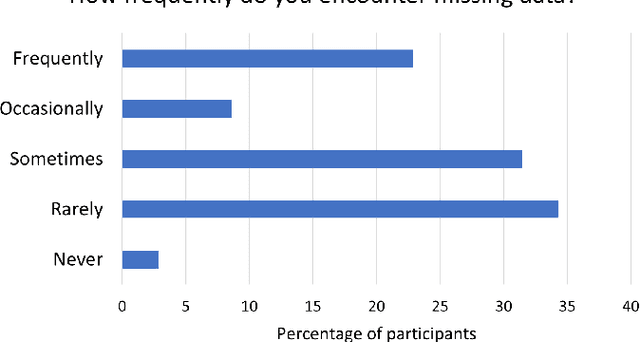
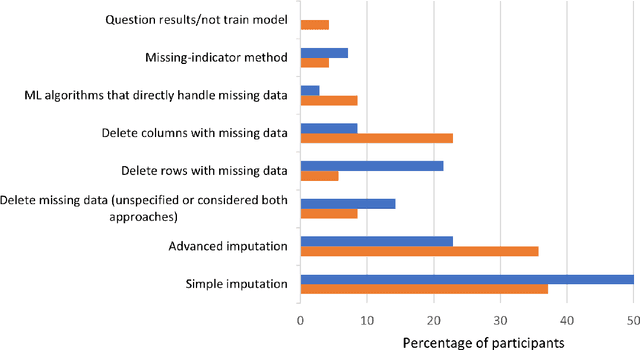
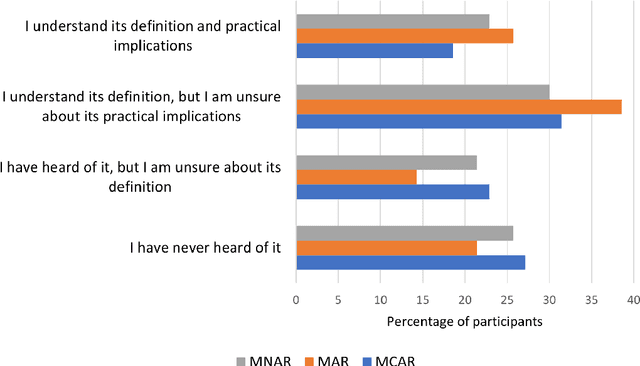
Missing data is prevalent in tabular machine learning (ML) models, and different missing data treatment methods can significantly affect ML model training results. However, little is known about how ML researchers and engineers choose missing data treatment methods and what factors affect their choices. To this end, we conducted a survey of 70 ML researchers and engineers. Our results revealed that most participants were not making informed decisions regarding missing data treatment, which could significantly affect the validity of the ML models trained by these researchers. We advocate for better education on missing data, more standardized missing data reporting, and better missing data analysis tools.
View paper on