 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgetmn at SemEval-2023 Task 9: Multilingual Tweet Intimacy Detection using XLM-T, Google Translate, and Ensemble Learning
Paper and Code

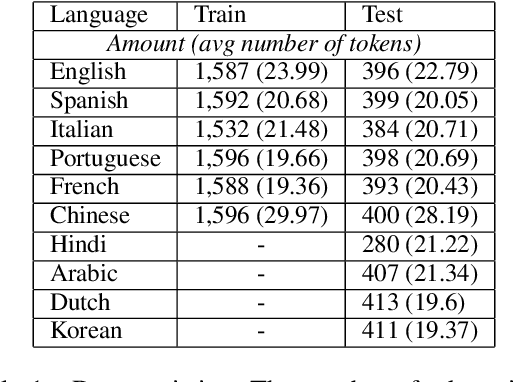


The paper describes a transformer-based system designed for SemEval-2023 Task 9: Multilingual Tweet Intimacy Analysis. The purpose of the task was to predict the intimacy of tweets in a range from 1 (not intimate at all) to 5 (very intimate). The official training set for the competition consisted of tweets in six languages (English, Spanish, Italian, Portuguese, French, and Chinese). The test set included the given six languages as well as external data with four languages not presented in the training set (Hindi, Arabic, Dutch, and Korean). We presented a solution based on an ensemble of XLM-T, a multilingual RoBERTa model adapted to the Twitter domain. To improve the performance of unseen languages, each tweet was supplemented by its English translation. We explored the effectiveness of translated data for the languages seen in fine-tuning compared to unseen languages and estimated strategies for using translated data in transformer-based models. Our solution ranked 4th on the leaderboard while achieving an overall Pearson's r of 0.599 over the test set. The proposed system improves up to 0.088 Pearson's r over a score averaged across all 45 submissions.