 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Will Change Things: An Empirical Study on Dynamic Language Understanding in Social Media Classification
Paper and Code
Oct 06, 2022
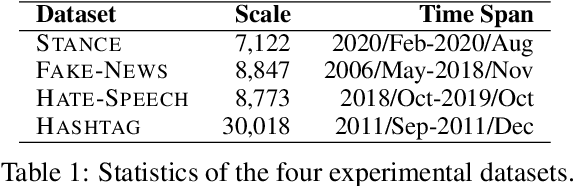
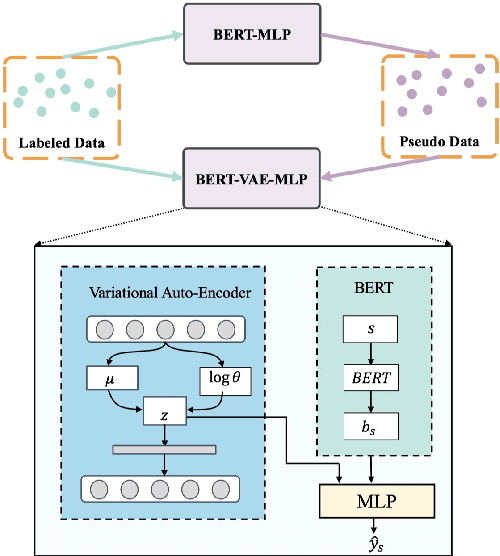
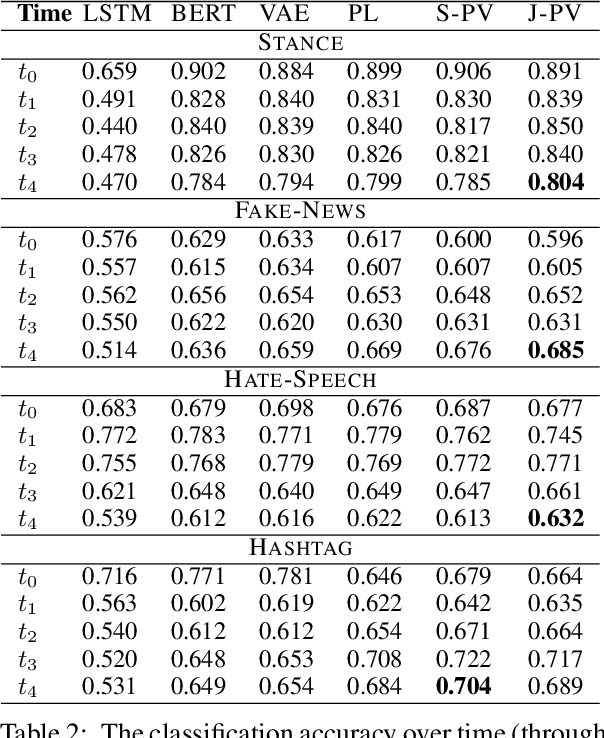
Language features are ever-evolving in the real-world social media environment. Many trained models in natural language understanding (NLU), ineffective in semantic inference for unseen features, might consequently struggle with the deteriorating performance in dynamicity. To address this challenge, we empirically study social media NLU in a dynamic setup, where models are trained on the past data and test on the future. It better reflects the realistic practice compared to the commonly-adopted static setup of random data split. To further analyze model adaption to the dynamicity, we explore the usefulness of leveraging some unlabeled data created after a model is trained. The performance of unsupervised domain adaption baselines based on auto-encoding and pseudo-labeling and a joint framework coupling them both are examined in the experiments. Substantial results on four social media tasks imply the universally negative effects of evolving environments over classification accuracy, while auto-encoding and pseudo-labeling collaboratively show the best robustness in dynamicity.