 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Matters: Scaling Laws for Any Budget
Paper and Code
Jun 27, 2024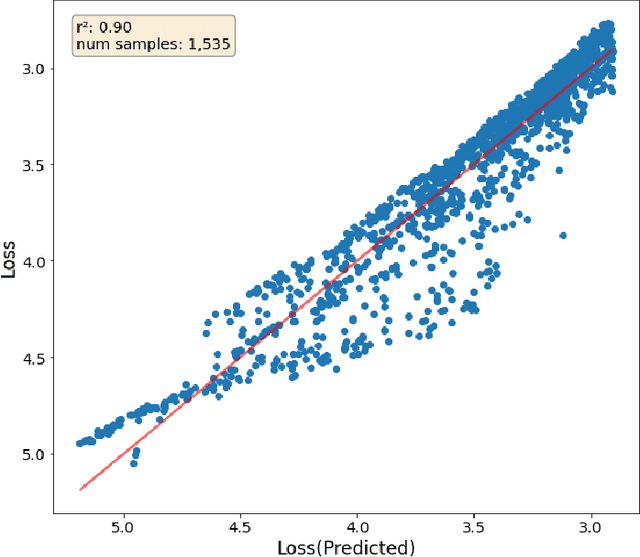
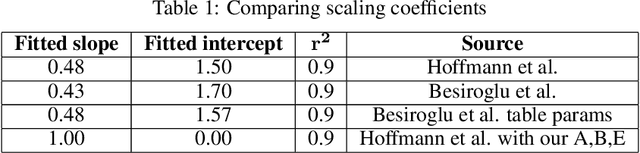
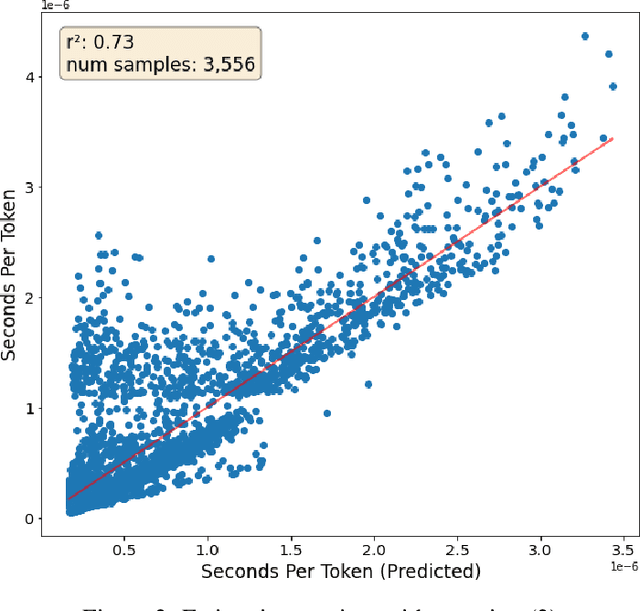

A primary cost driver for training large models is wall-clock training time. We show that popular time estimates based on FLOPs are poor estimates, and construct a more accurate proxy based on memory copies. We show that with some simple accounting, we can estimate the training speed of a transformer model from its hyperparameters. Combined with a scaling law curve like Chinchilla, this lets us estimate the final loss of the model. We fit our estimate to real data with a linear regression, and apply the result to rewrite Chinchilla in terms of a model's estimated training time as opposed to the amount of training data. This gives an expression for the loss in terms of the model's hyperparameters alone. We show that this expression is accurate across a wide range of model hyperparameter values, enabling us to analytically make architectural decisions and train models more efficiently.