 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThesis proposal: Are We Losing Textual Diversity to Natural Language Processing?
Paper and Code
Sep 15, 2024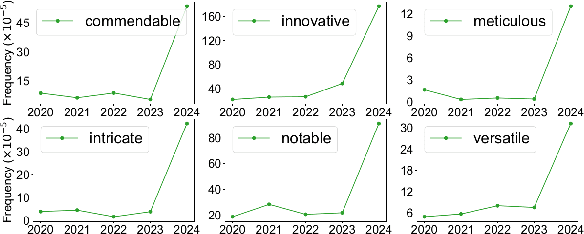

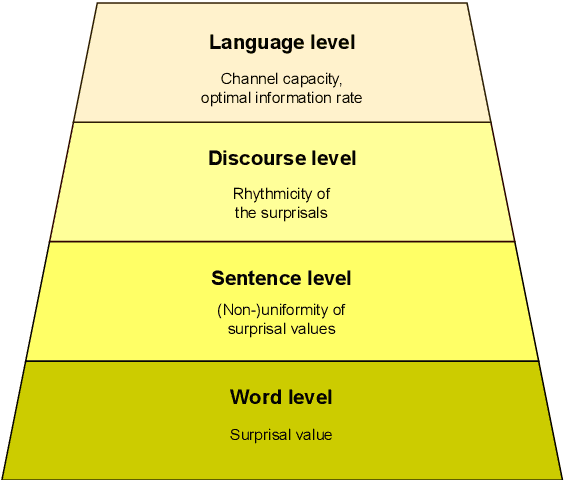

This thesis argues that the currently widely used Natural Language Processing algorithms possibly have various limitations related to the properties of the texts they handle and produce. With the wide adoption of these tools in rapid progress, we must ask what these limitations are and what are the possible implications of integrating such tools even more deeply into our daily lives. As a testbed, we have chosen the task of Neural Machine Translation (NMT). Nevertheless, we aim for general insights and outcomes, applicable even to current Large Language Models (LLMs). We ask whether the algorithms used in NMT have inherent inductive biases that are beneficial for most types of inputs but might harm the processing of untypical texts. To explore this hypothesis, we define a set of measures to quantify text diversity based on its statistical properties, like uniformity or rhythmicity of word-level surprisal, on multiple scales (sentence, discourse, language). We then conduct a series of experiments to investigate whether NMT systems struggle with maintaining the diversity of such texts, potentially reducing the richness of the language generated by these systems, compared to human translators. We search for potential causes of these limitations rooted in training objectives and decoding algorithms. Our ultimate goal is to develop alternatives that do not enforce uniformity in the distribution of statistical properties in the output and that allow for better global planning of the translation, taking into account the intrinsic ambiguity of the translation task.