 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory of Deep Q-Learning: A Dynamical Systems Perspective
Paper and Code
Aug 25, 2020
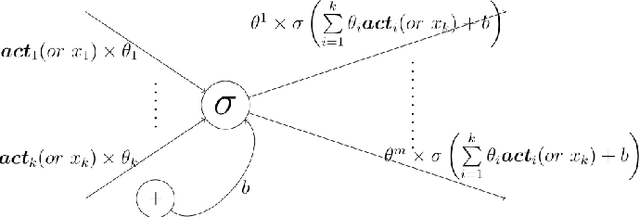

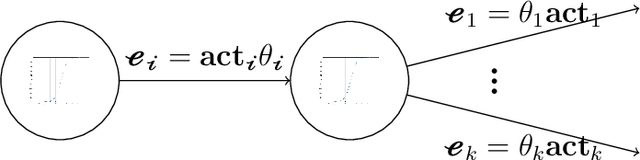
Deep Q-Learning is an important algorithm, used to solve sequential decision making problems. It involves training a Deep Neural Network, called a Deep Q-Network (DQN), to approximate a function associated with optimal decision making, the Q-function. Although wildly successful in laboratory conditions, serious gaps between theory and practice prevent its use in the real-world. In this paper, we present a comprehensive analysis of the popular and practical version of the algorithm, under realistic verifiable assumptions. An important contribution is the characterization of its performance as a function of training. To do this, we view the algorithm as an evolving dynamical system. This facilitates associating a closely-related measure process with training. Then, the long-term behavior of Deep Q-Learning is determined by the limit of the aforementioned measure process. Empirical inferences, such as the qualitative advantage of using experience replay, and performance inconsistencies even after training, are explained using our analysis. Also, our theory is general and accommodates state Markov processes with multiple stationary distributions.