Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe WiLI benchmark dataset for written language identification
Paper and Code
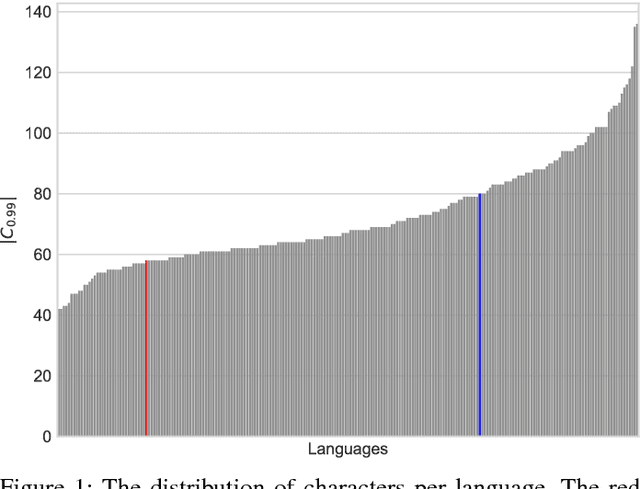
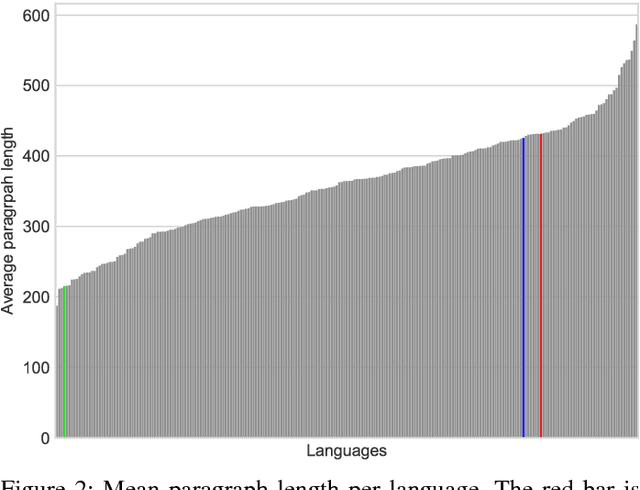

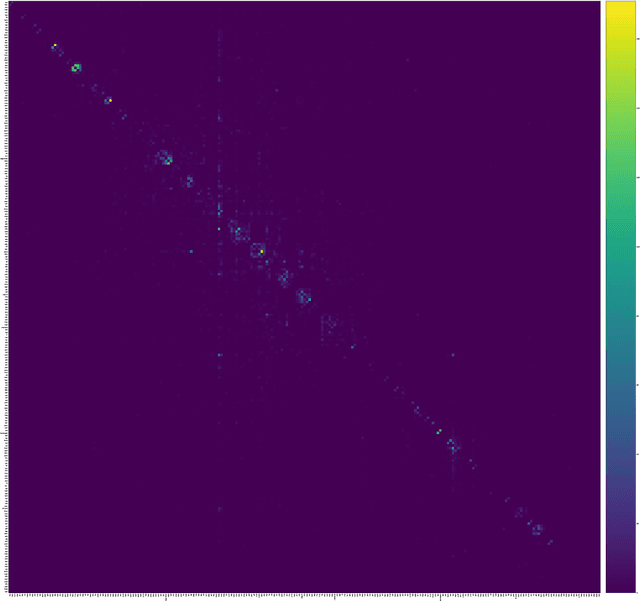
This paper describes the WiLI-2018 benchmark dataset for monolingual written natural language identification. WiLI-2018 is a publicly available, free of charge dataset of short text extracts from Wikipedia. It contains 1000 paragraphs of 235 languages, totaling in 23500 paragraphs. WiLI is a classification dataset: Given an unknown paragraph written in one dominant language, it has to be decided which language it is.
* {"pages": 12, "figures": 4, "language": "English", "author-ORCiD":
["https://orcid.org/0000-0002-6517-1690"]}
View paper on