 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trumpiest Trump? Identifying a Subject's Most Characteristic Tweets
Paper and Code
Sep 09, 2019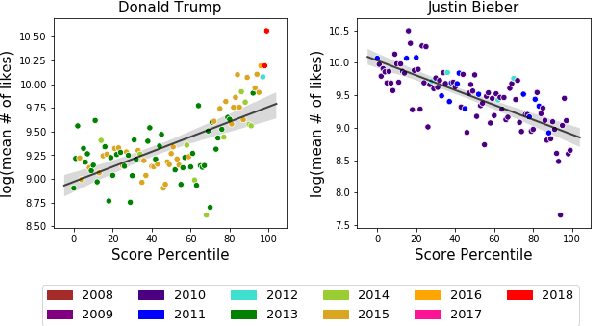
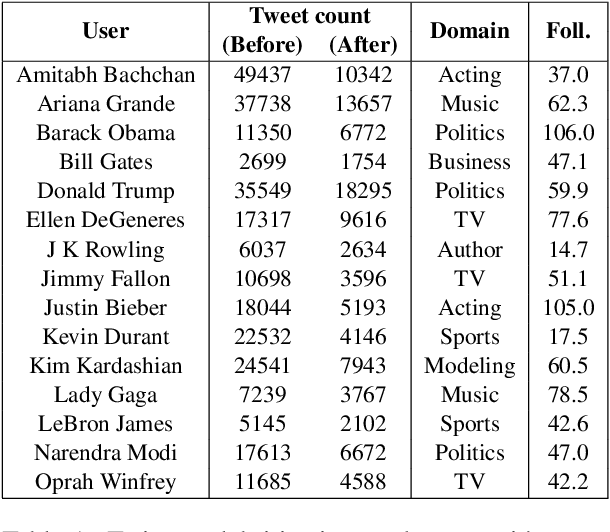


The sequence of documents produced by any given author varies in style and content, but some documents are more typical or representative of the source than others. We quantify the extent to which a given short text is characteristic of a specific person, using a dataset of tweets from fifteen celebrities. Such analysis is useful for generating excerpts of high-volume Twitter profiles, and understanding how representativeness relates to tweet popularity. We first consider the related task of binary author detection (is x the author of text T?), and report a test accuracy of 90.37% for the best of five approaches to this problem. We then use these models to compute characterization scores among all of an author's texts. A user study shows human evaluators agree with our characterization model for all 15 celebrities in our dataset, each with p-value < 0.05. We use these classifiers to show surprisingly strong correlations between characterization scores and the popularity of the associated texts. Indeed, we demonstrate a statistically significant correlation between this score and tweet popularity (likes/replies/retweets) for 13 of the 15 celebrities in our study.