Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Stroke Correspondence Problem, Revisited
Paper and Code
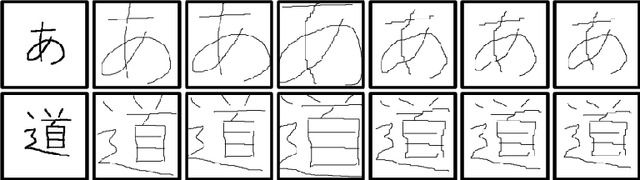
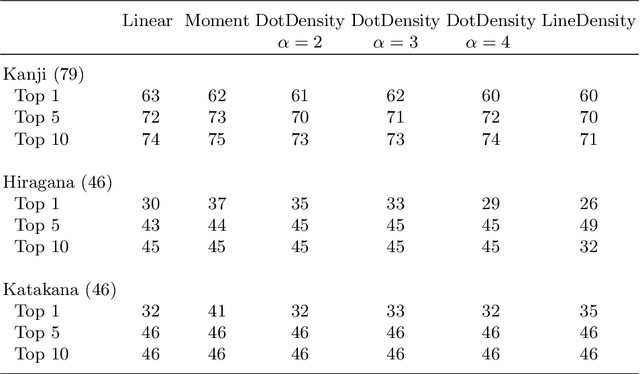
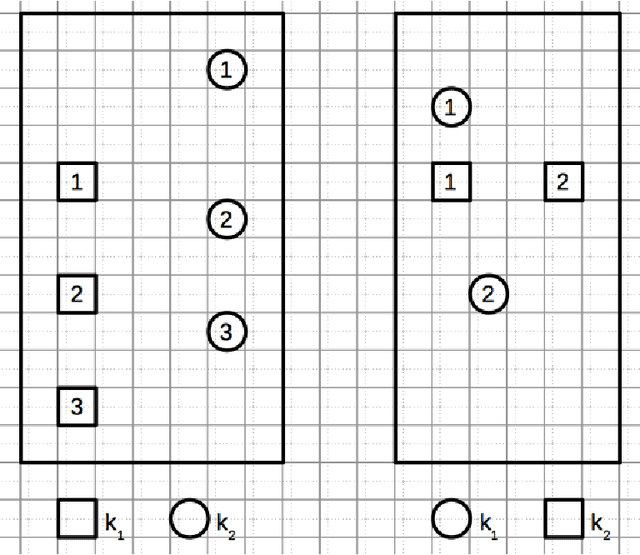
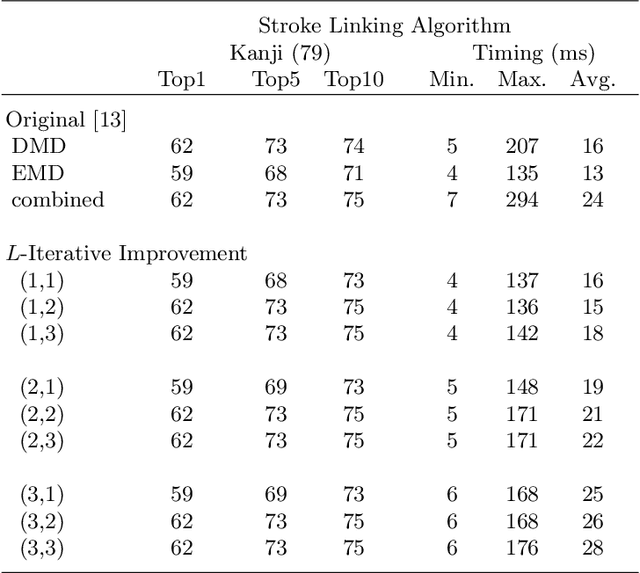
We revisit the stroke correspondence problem [13,14]. We optimize this algorithm by 1) evaluating suitable preprocessing (normalization) methods 2) extending the algorithm with an additional distance measure to handle Hiragana, Katakana and Kanji characters with a low number of strokes and c) simplify the stroke linking algorithms. Our contributions are implemented in the free, open-source library ctegaki and in the demo-tools jTegaki and Kanjicanvas.
* 16 pages, 2 figures
View paper on