 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Secret Source : Incorporating Source Features to Improve Acoustic-to-Articulatory Speech Inversion
Paper and Code
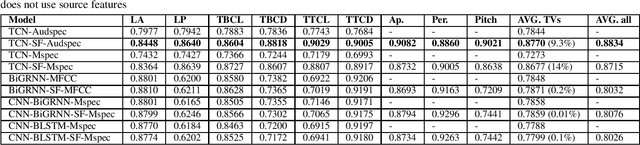
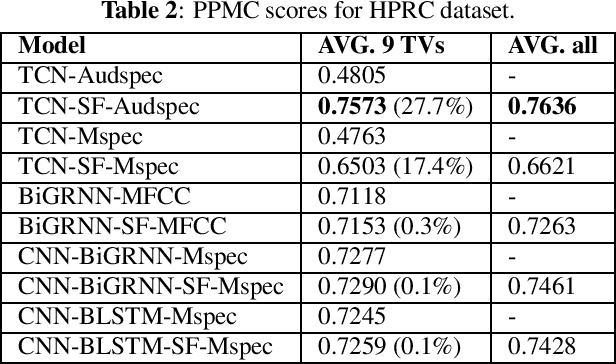
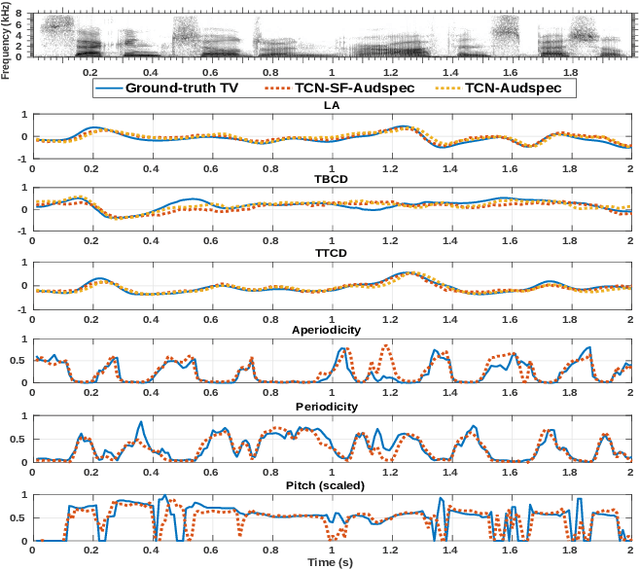
In this work, we incorporated acoustically derived source features, aperiodicity, periodicity and pitch as additional targets to an acoustic-to-articulatory speech inversion (SI) system. We also propose a Temporal Convolution based SI system, which uses auditory spectrograms as the input speech representation, to learn long-range dependencies and complex interactions between the source and vocal tract, to improve the SI task. The experiments are conducted with both the Wisconsin X-ray microbeam (XRMB) and Haskins Production Rate Comparison (HPRC) datasets, with comparisons done with respect to three baseline SI model architectures. The proposed SI system with the HPRC dataset gains an improvement of close to 28% when the source features are used as additional targets. The same SI system outperforms the current best performing SI models by around 9% on the XRMB dataset.