 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role Of Biology In Deep Learning
Paper and Code
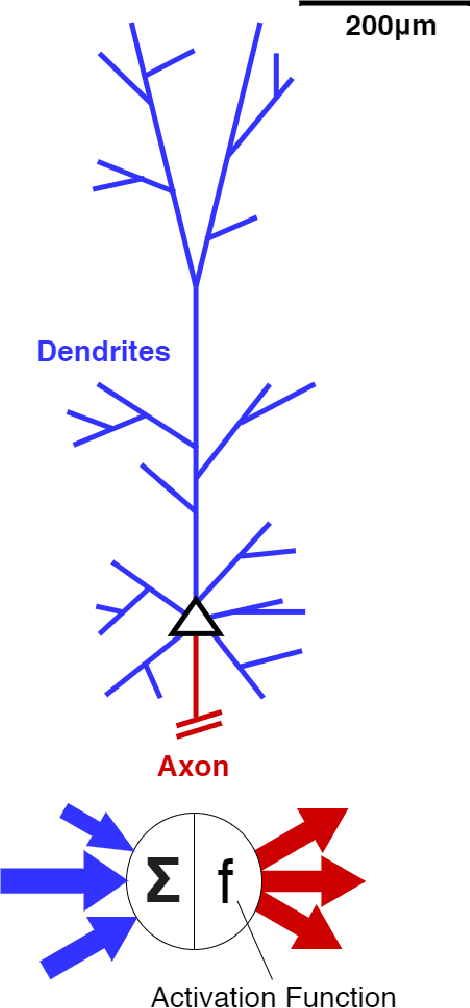
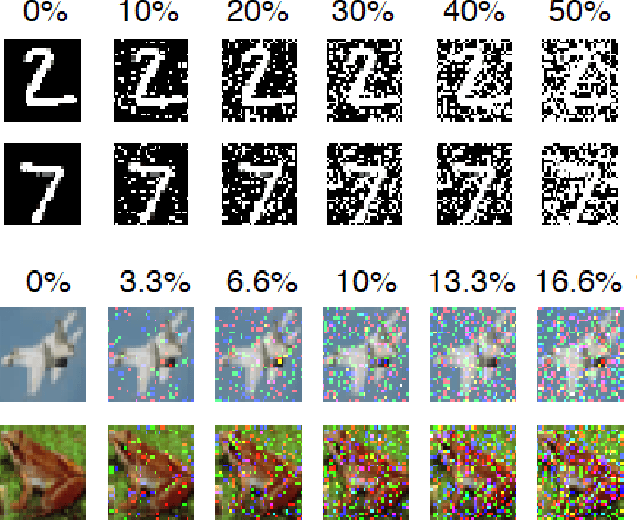
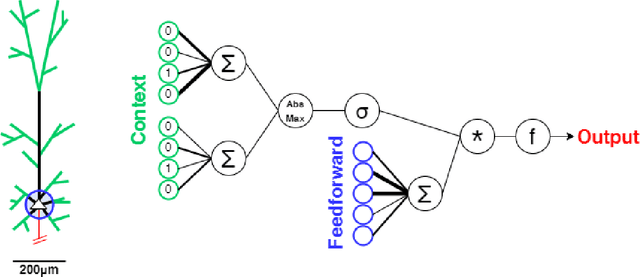
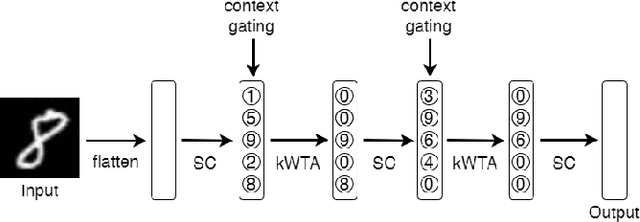
Artificial neural networks took a lot of inspiration from their biological counterparts in becoming our best machine perceptual systems. This work summarizes some of that history and incorporates modern theoretical neuroscience into experiments with artificial neural networks from the field of deep learning. Specifically, iterative magnitude pruning is used to train sparsely connected networks with 33x fewer weights without loss in performance. These are used to test and ultimately reject the hypothesis that weight sparsity alone improves image noise robustness. Recent work mitigated catastrophic forgetting using weight sparsity, activation sparsity, and active dendrite modeling. This paper replicates those findings, and extends the method to train convolutional neural networks on a more challenging continual learning task. The code has been made publicly available.