 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Programming of Deep Learning Accelerators as a Constraint Satisfaction Problem
Paper and Code
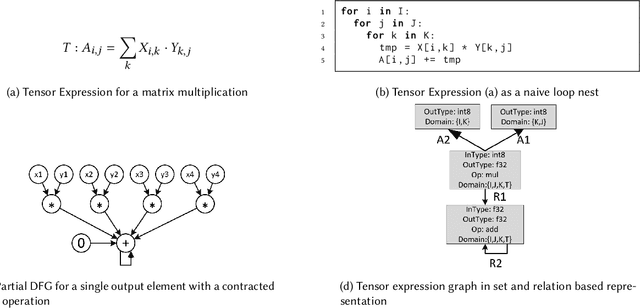
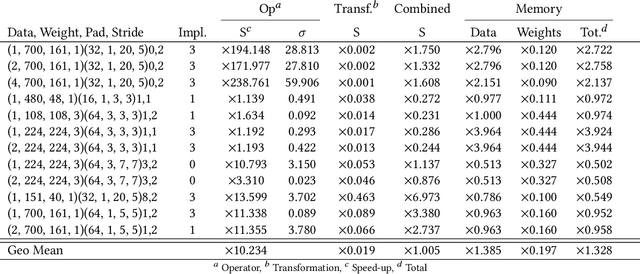

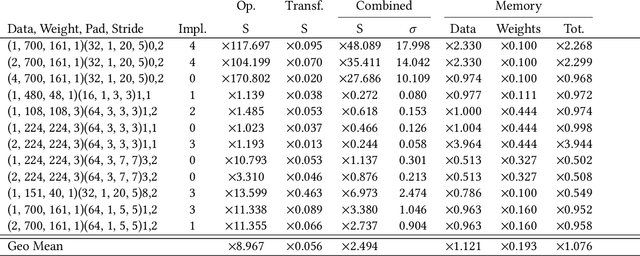
The success of Deep Artificial Neural Networks (DNNs) in many domains created a rich body of research concerned with hardware accelerators for compute-intensive DNN operators. However, implementing such operators efficiently with complex instructions such as matrix multiply is a task not yet automated gracefully. Solving this task often requires complex program and memory layout transformations. First solutions to this problem have been proposed, such as TVM or ISAMIR, which work on a loop-level representation of operators and rewrite the program before an instruction embedding into the operator is performed. This top-down approach creates a tension between exploration range and search space complexity. In this work, we propose a new approach to this problem. We have created a bottom-up method that allows the direct generation of implementations based on an accelerator's instruction set. By formulating the embedding as a constraint satisfaction problem over the scalar dataflow, every possible embedding solution is contained in the search space. By adding additional constraints, a solver can produce the subset of preferable solutions. A detailed evaluation using the VTA hardware accelerator with the Baidu DeepBench inference benchmark suite shows that our approach can automatically generate code competitive to reference implementations, and furthermore that memory layout flexibilty can be beneficial for overall performance. While the reference implementation achieves very low hardware utilization due to its fixed embedding strategy, we achieve a geomean speedup of up to x2.49, while individual operators can improve as much as x238.