 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Few: Accelerating and Enhancing Data Reweighting with Coreset Selection
Paper and Code
Mar 20, 2024


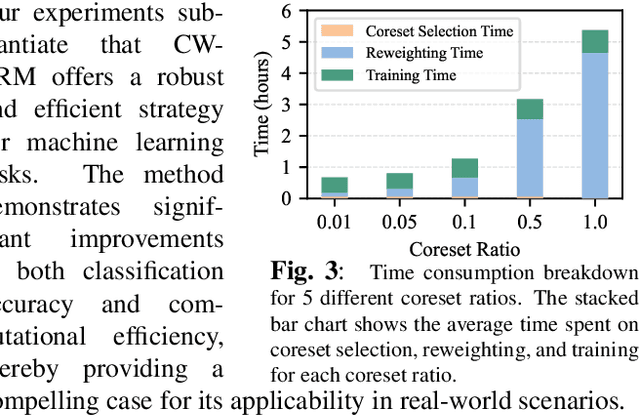
As machine learning tasks continue to evolve, the trend has been to gather larger datasets and train increasingly larger models. While this has led to advancements in accuracy, it has also escalated computational costs to unsustainable levels. Addressing this, our work aims to strike a delicate balance between computational efficiency and model accuracy, a persisting challenge in the field. We introduce a novel method that employs core subset selection for reweighting, effectively optimizing both computational time and model performance. By focusing on a strategically selected coreset, our approach offers a robust representation, as it efficiently minimizes the influence of outliers. The re-calibrated weights are then mapped back to and propagated across the entire dataset. Our experimental results substantiate the effectiveness of this approach, underscoring its potential as a scalable and precise solution for model training.