 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PITA System: Tabling and Answer Subsumption for Reasoning under Uncertainty
Paper and Code
Jul 24, 2011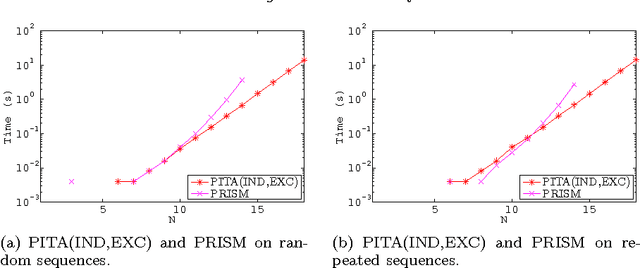

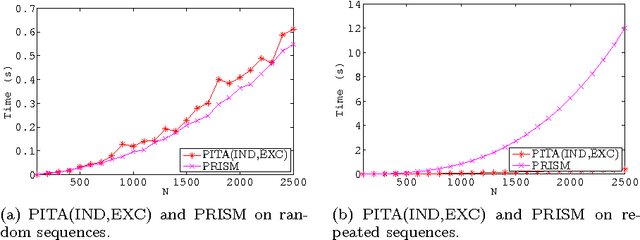
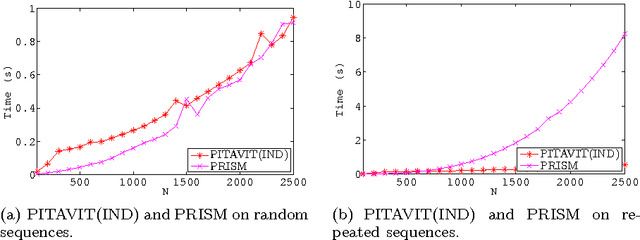
Many real world domains require the representation of a measure of uncertainty. The most common such representation is probability, and the combination of probability with logic programs has given rise to the field of Probabilistic Logic Programming (PLP), leading to languages such as the Independent Choice Logic, Logic Programs with Annotated Disjunctions (LPADs), Problog, PRISM and others. These languages share a similar distribution semantics, and methods have been devised to translate programs between these languages. The complexity of computing the probability of queries to these general PLP programs is very high due to the need to combine the probabilities of explanations that may not be exclusive. As one alternative, the PRISM system reduces the complexity of query answering by restricting the form of programs it can evaluate. As an entirely different alternative, Possibilistic Logic Programs adopt a simpler metric of uncertainty than probability. Each of these approaches -- general PLP, restricted PLP, and Possibilistic Logic Programming -- can be useful in different domains depending on the form of uncertainty to be represented, on the form of programs needed to model problems, and on the scale of the problems to be solved. In this paper, we show how the PITA system, which originally supported the general PLP language of LPADs, can also efficiently support restricted PLP and Possibilistic Logic Programs. PITA relies on tabling with answer subsumption and consists of a transformation along with an API for library functions that interface with answer subsumption.