 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Phonexia VoxCeleb Speaker Recognition Challenge 2021 System Description
Paper and Code
Sep 08, 2021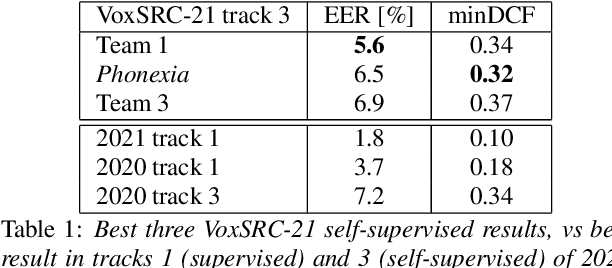
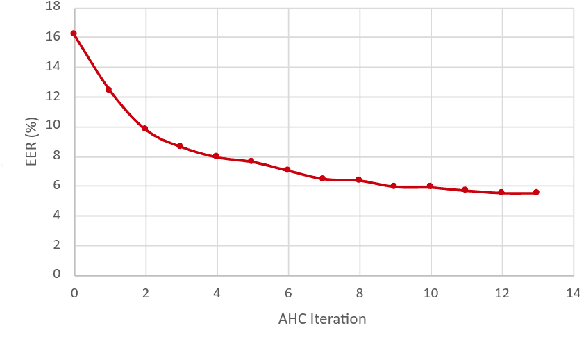
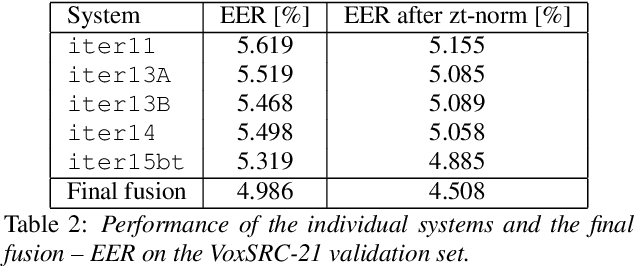

We describe the Phonexia submission for the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21) in the unsupervised speaker verification track. Our solution was very similar to IDLab's winning submission for VoxSRC-20. An embedding extractor was bootstrapped using momentum contrastive learning, with input augmentations as the only source of supervision. This was followed by several iterations of clustering to assign pseudo-speaker labels that were then used for supervised embedding extractor training. Finally, a score fusion was done, by averaging the zt-normalized cosine scores of five different embedding extractors. We briefly also describe unsuccessful solutions involving i-vectors instead of DNN embeddings and PLDA instead of cosine scoring.