Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Neural Painter: Multi-Turn Image Generation
Paper and Code
Jun 16, 2018
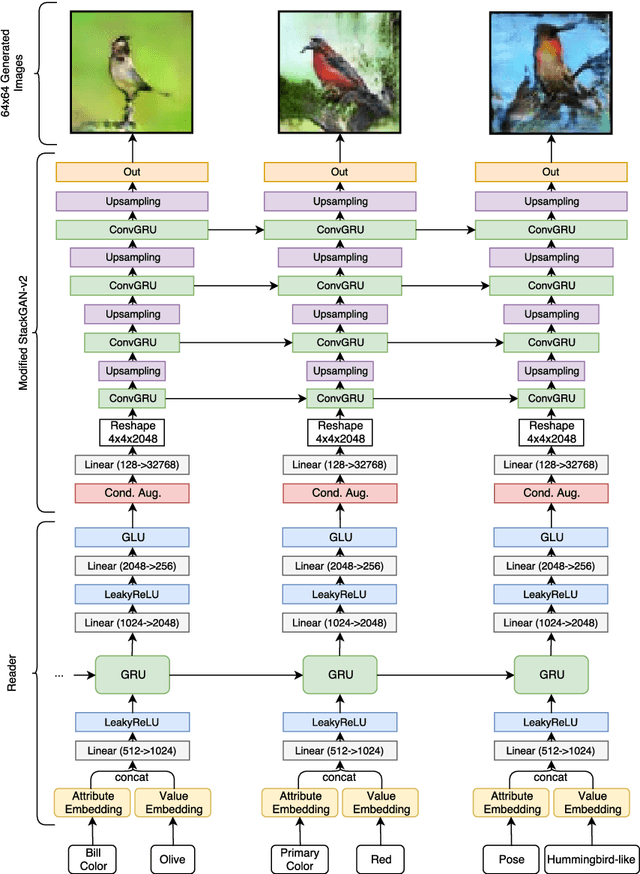
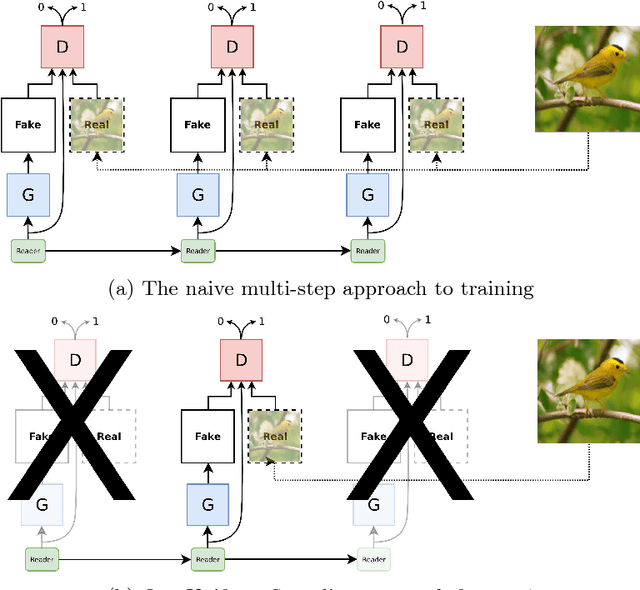

In this work we combine two research threads from Vision/ Graphics and Natural Language Processing to formulate an image generation task conditioned on attributes in a multi-turn setting. By multiturn, we mean the image is generated in a series of steps of user-specified conditioning information. Our proposed approach is practically useful and offers insights into neural interpretability. We introduce a framework that includes a novel training algorithm as well as model improvements built for the multi-turn setting. We demonstrate that this framework generates a sequence of images that match the given conditioning information and that this task is useful for more detailed benchmarking and analysis of conditional image generation methods.
View paper on