 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Learnability of Unknown Quantum Measurements
Paper and Code
Jan 03, 2015

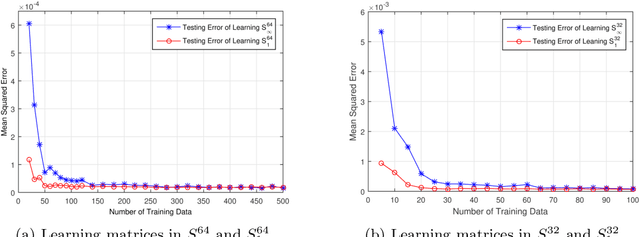

Quantum machine learning has received significant attention in recent years, and promising progress has been made in the development of quantum algorithms to speed up traditional machine learning tasks. In this work, however, we focus on investigating the information-theoretic upper bounds of sample complexity - how many training samples are sufficient to predict the future behaviour of an unknown target function. This kind of problem is, arguably, one of the most fundamental problems in statistical learning theory and the bounds for practical settings can be completely characterised by a simple measure of complexity. Our main result in the paper is that, for learning an unknown quantum measurement, the upper bound, given by the fat-shattering dimension, is linearly proportional to the dimension of the underlying Hilbert space. Learning an unknown quantum state becomes a dual problem to ours, and as a byproduct, we can recover Aaronson's famous result [Proc. R. Soc. A 463:3089-3144 (2007)] solely using a classical machine learning technique. In addition, other famous complexity measures like covering numbers and Rademacher complexities are derived explicitly. We are able to connect measures of sample complexity with various areas in quantum information science, e.g. quantum state/measurement tomography, quantum state discrimination and quantum random access codes, which may be of independent interest. Lastly, with the assistance of general Bloch-sphere representation, we show that learning quantum measurements/states can be mathematically formulated as a neural network. Consequently, classical ML algorithms can be applied to efficiently accomplish the two quantum learning tasks.