 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe large learning rate phase of deep learning: the catapult mechanism
Paper and Code
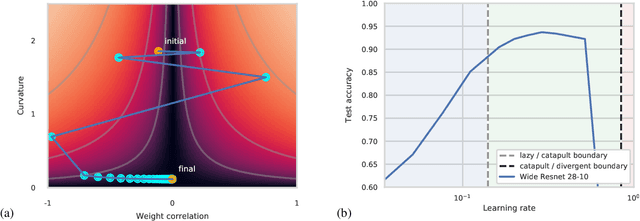
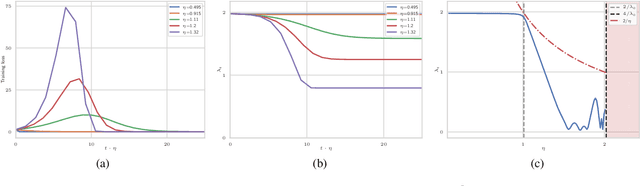
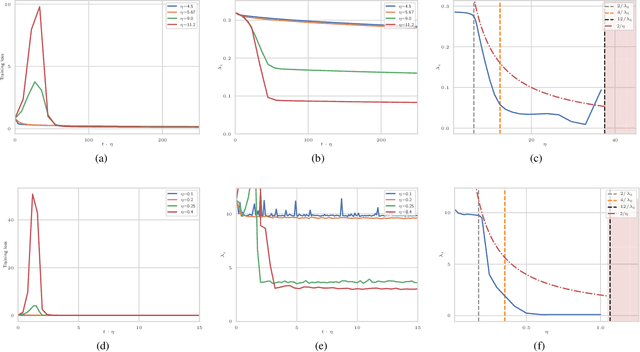
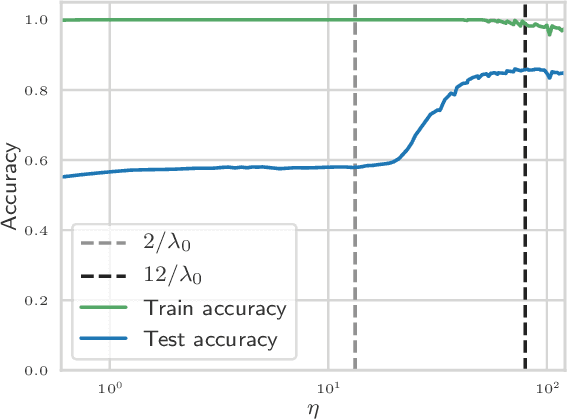
The choice of initial learning rate can have a profound effect on the performance of deep networks. We present a class of neural networks with solvable training dynamics, and confirm their predictions empirically in practical deep learning settings. The networks exhibit sharply distinct behaviors at small and large learning rates. The two regimes are separated by a phase transition. In the small learning rate phase, training can be understood using the existing theory of infinitely wide neural networks. At large learning rates the model captures qualitatively distinct phenomena, including the convergence of gradient descent dynamics to flatter minima. One key prediction of our model is a narrow range of large, stable learning rates. We find good agreement between our model's predictions and training dynamics in realistic deep learning settings. Furthermore, we find that the optimal performance in such settings is often found in the large learning rate phase. We believe our results shed light on characteristics of models trained at different learning rates. In particular, they fill a gap between existing wide neural network theory, and the nonlinear, large learning rate, training dynamics relevant to practice.