 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lab vs The Crowd: An Investigation into Data Quality for Neural Dialogue Models
Paper and Code
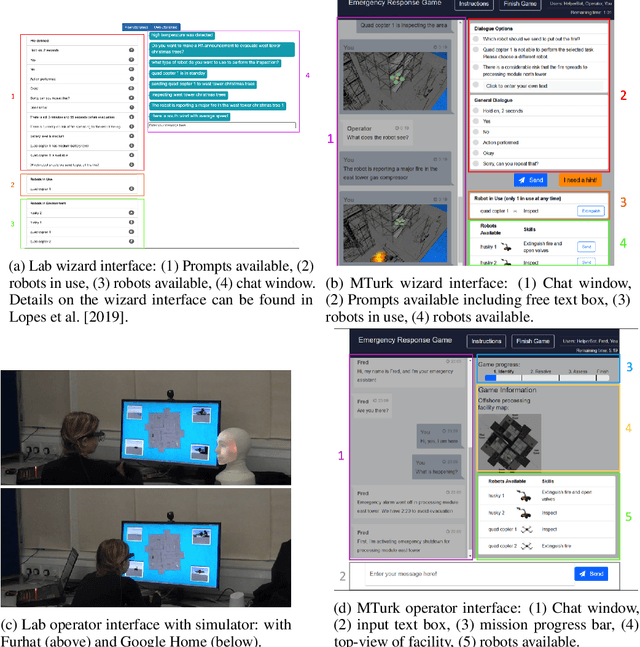
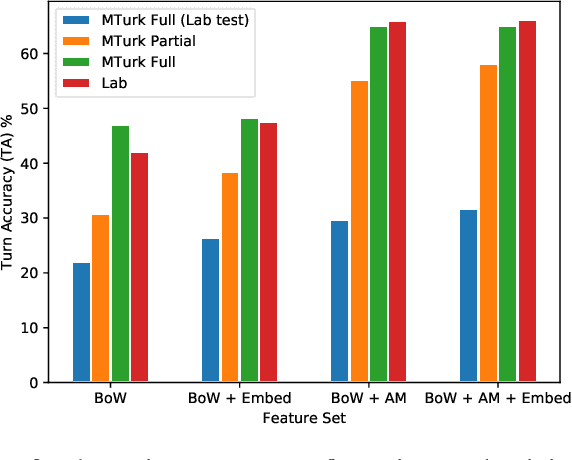
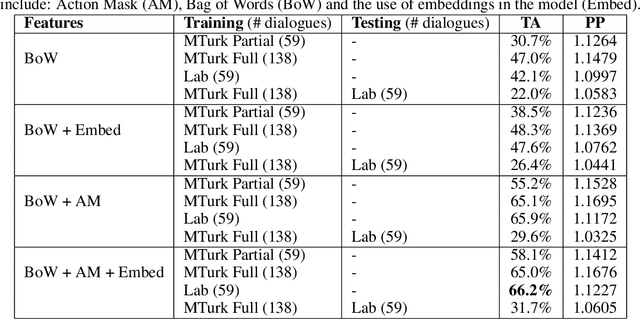

Challenges around collecting and processing quality data have hampered progress in data-driven dialogue models. Previous approaches are moving away from costly, resource-intensive lab settings, where collection is slow but where the data is deemed of high quality. The advent of crowd-sourcing platforms, such as Amazon Mechanical Turk, has provided researchers with an alternative cost-effective and rapid way to collect data. However, the collection of fluid, natural spoken or textual interaction can be challenging, particularly between two crowd-sourced workers. In this study, we compare the performance of dialogue models for the same interaction task but collected in two different settings: in the lab vs. crowd-sourced. We find that fewer lab dialogues are needed to reach similar accuracy, less than half the amount of lab data as crowd-sourced data. We discuss the advantages and disadvantages of each data collection method.