 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Inverse Bagging Algorithm: Anomaly Detection by Inverse Bootstrap Aggregating
Paper and Code
Nov 24, 2016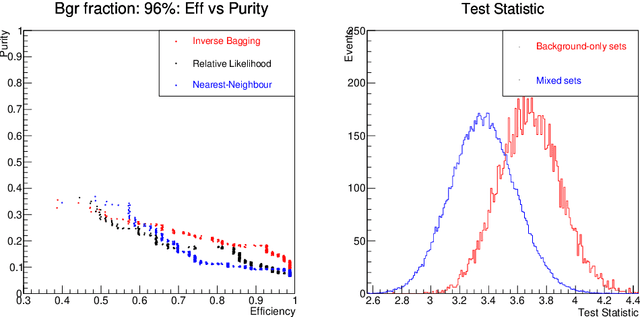
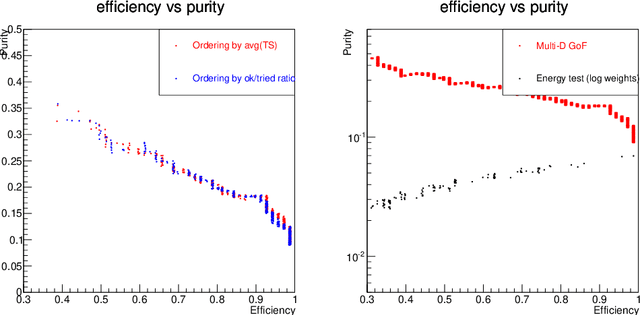
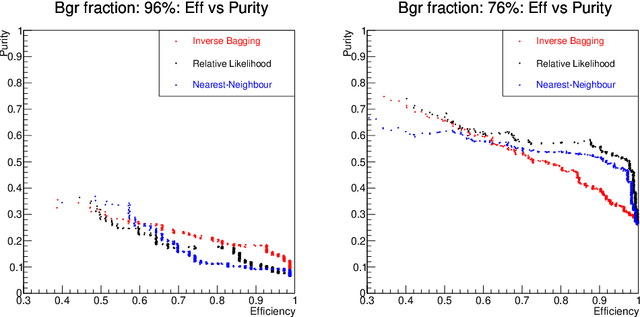
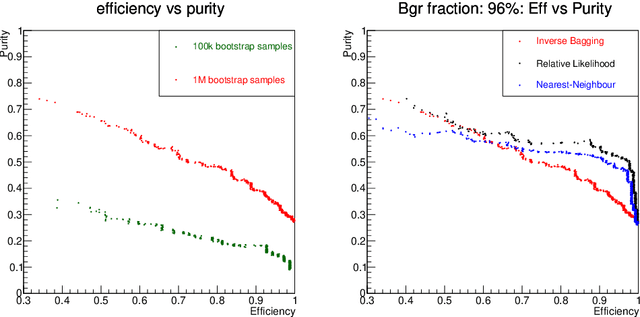
For data sets populated by a very well modeled process and by another process of unknown probability density function (PDF), a desired feature when manipulating the fraction of the unknown process (either for enhancing it or suppressing it) consists in avoiding to modify the kinematic distributions of the well modeled one. A bootstrap technique is used to identify sub-samples rich in the well modeled process, and classify each event according to the frequency of it being part of such sub-samples. Comparisons with general MVA algorithms will be shown, as well as a study of the asymptotic properties of the method, making use of a public domain data set that models a typical search for new physics as performed at hadronic colliders such as the Large Hadron Collider (LHC).