 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interpretable Dictionary in Sparse Coding
Paper and Code
Nov 24, 2020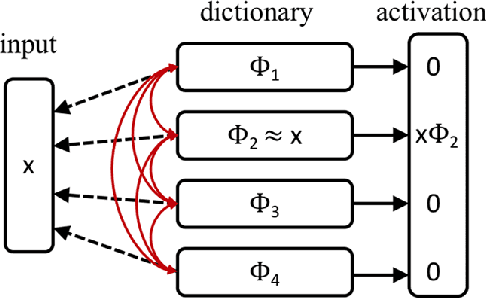
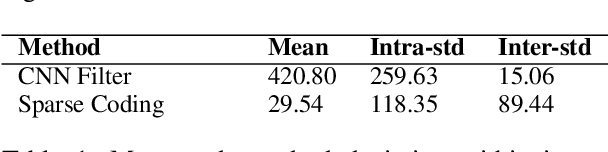


Artificial neural networks (ANNs), specifically deep learning networks, have often been labeled as black boxes due to the fact that the internal representation of the data is not easily interpretable. In our work, we illustrate that an ANN, trained using sparse coding under specific sparsity constraints, yields a more interpretable model than the standard deep learning model. The dictionary learned by sparse coding can be more easily understood and the activations of these elements creates a selective feature output. We compare and contrast our sparse coding model with an equivalent feed forward convolutional autoencoder trained on the same data. Our results show both qualitative and quantitative benefits in the interpretation of the learned sparse coding dictionary as well as the internal activation representations.