 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe information of attribute uncertainties: what convolutional neural networks can learn about errors in input data
Paper and Code
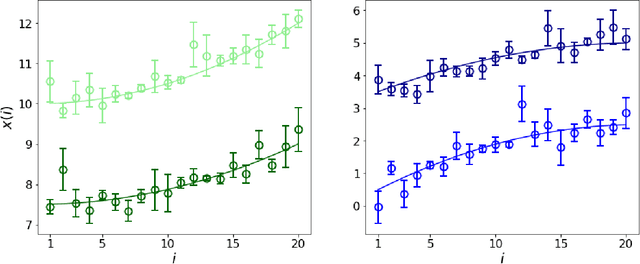

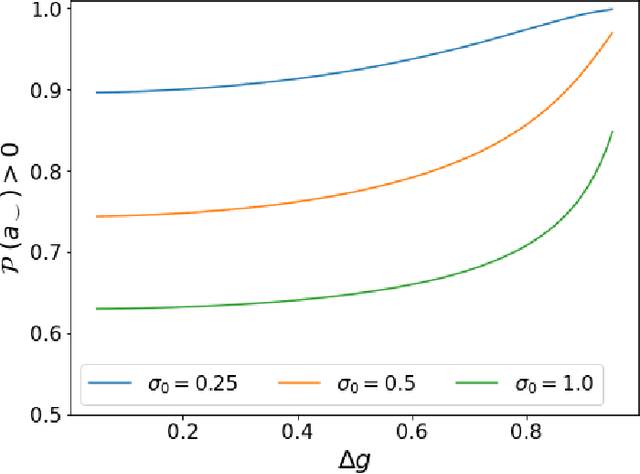
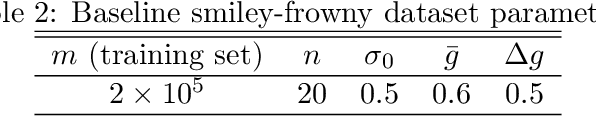
Errors in measurements are key to weighting the value of data, but are often neglected in Machine Learning (ML). We show how Convolutional Neural Networks (CNNs) are able to learn about the context and patterns of signal and noise, leading to improvements in the performance of classification methods. We construct a model whereby two classes of objects follow an underlying Gaussian distribution, and where the features (the input data) have varying, but known, levels of noise. This model mimics the nature of scientific data sets, where the noises arise as realizations of some random processes whose underlying distributions are known. The classification of these objects can then be performed using standard statistical techniques (e.g., least-squares minimization or Markov-Chain Monte Carlo), as well as ML techniques. This allows us to take advantage of a maximum likelihood approach to object classification, and to measure the amount by which the ML methods are incorporating the information in the input data uncertainties. We show that, when each data point is subject to different levels of noise (i.e., noises with different distribution functions), that information can be learned by the CNNs, raising the ML performance to at least the same level of the least-squares method -- and sometimes even surpassing it. Furthermore, we show that, with varying noise levels, the confidence of the ML classifiers serves as a proxy for the underlying cumulative distribution function, but only if the information about specific input data uncertainties is provided to the CNNs.