 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Implicit Bias of Gradient Descent on Generalized Gated Linear Networks
Paper and Code
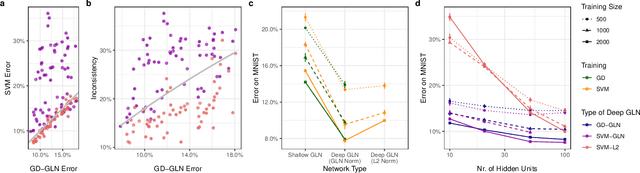

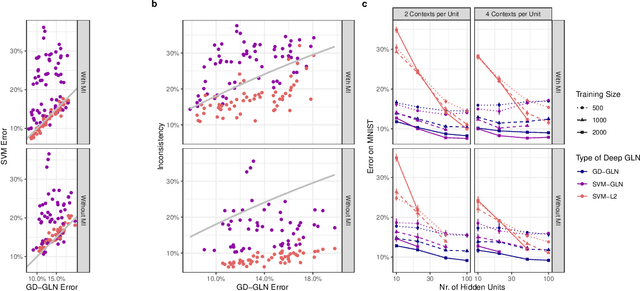
Understanding the asymptotic behavior of gradient-descent training of deep neural networks is essential for revealing inductive biases and improving network performance. We derive the infinite-time training limit of a mathematically tractable class of deep nonlinear neural networks, gated linear networks (GLNs), and generalize these results to gated networks described by general homogeneous polynomials. We study the implications of our results, focusing first on two-layer GLNs. We then apply our theoretical predictions to GLNs trained on MNIST and show how architectural constraints and the implicit bias of gradient descent affect performance. Finally, we show that our theory captures a substantial portion of the inductive bias of ReLU networks. By making the inductive bias explicit, our framework is poised to inform the development of more efficient, biologically plausible, and robust learning algorithms.