 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of an Inter-rater Bias on Neural Network Training
Paper and Code
Jun 12, 2019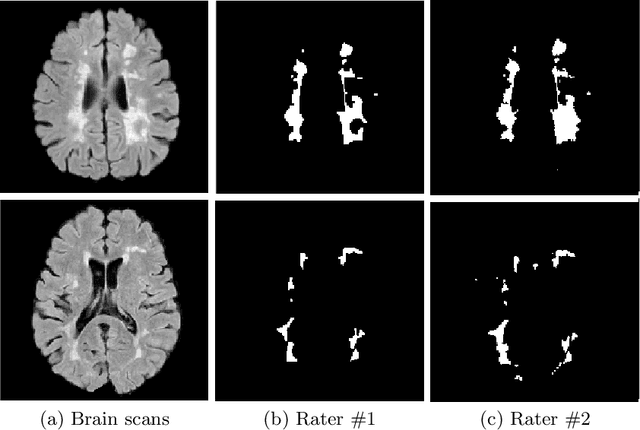

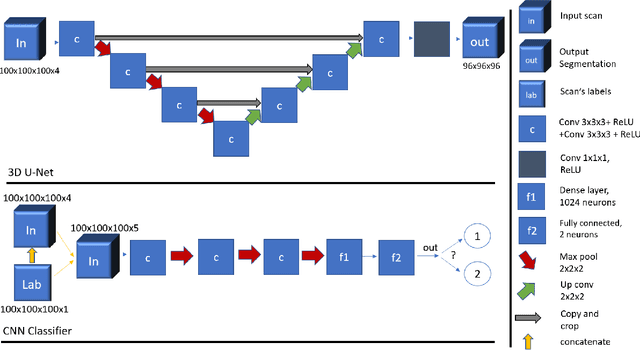

The problem of inter-rater variability is often discussed in the context of manual labeling of medical images. It is assumed to be bypassed by automatic model-based approaches for image segmentation which are considered `objective', providing single, deterministic solutions. However, the emergence of data-driven approaches such as Deep Neural Networks (DNNs) and their application to supervised semantic segmentation - brought this issue of raters' disagreement back to the front-stage. In this paper, we highlight the issue of inter-rater bias as opposed to random inter-observer variability and demonstrate its influence on DNN training, leading to different segmentation results for the same input images. In fact, lower Dice scores are calculated if training and test segmentations are of different raters. Moreover, we demonstrate that inter-rater bias in the training examples is amplified when considering the segmentation predictions for the test data. We support our findings by showing that a classifier-DNN trained to distinguish between raters based on their manual annotations performs better when the automatic segmentation predictions rather than the raters' annotations were tested. For this study, we used the ISBI 2015 Multiple Sclerosis (MS) challenge dataset, which includes annotations by two raters with different levels of expertise. The results obtained allow us to underline a worrisome clinical implication of a DNN bias induced by an inter-rater bias during training. Specially, we show that the differences in MS-lesion load estimates increase when the volume calculations are done based on the DNNs' segmentation predictions instead of the manual annotations used for training.