 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ghost in the Machine has an American accent: value conflict in GPT-3
Paper and Code
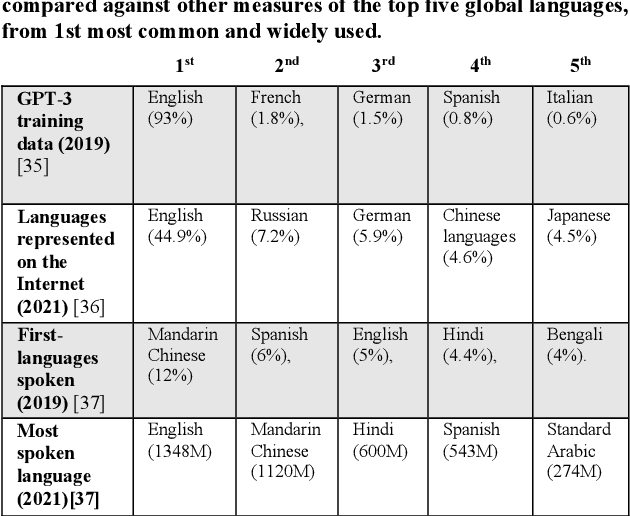
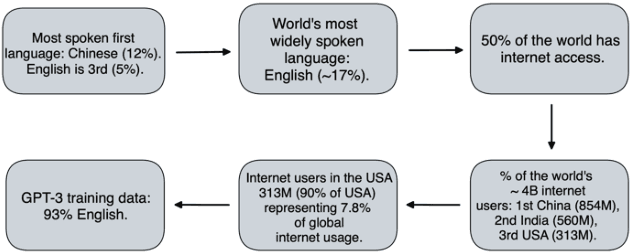
The alignment problem in the context of large language models must consider the plurality of human values in our world. Whilst there are many resonant and overlapping values amongst the world's cultures, there are also many conflicting, yet equally valid, values. It is important to observe which cultural values a model exhibits, particularly when there is a value conflict between input prompts and generated outputs. We discuss how the co-creation of language and cultural value impacts large language models (LLMs). We explore the constitution of the training data for GPT-3 and compare that to the world's language and internet access demographics, as well as to reported statistical profiles of dominant values in some Nation-states. We stress tested GPT-3 with a range of value-rich texts representing several languages and nations; including some with values orthogonal to dominant US public opinion as reported by the World Values Survey. We observed when values embedded in the input text were mutated in the generated outputs and noted when these conflicting values were more aligned with reported dominant US values. Our discussion of these results uses a moral value pluralism (MVP) lens to better understand these value mutations. Finally, we provide recommendations for how our work may contribute to other current work in the field.