 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effectiveness of Temporal Dependency in Deepfake Video Detection
Paper and Code
May 13, 2022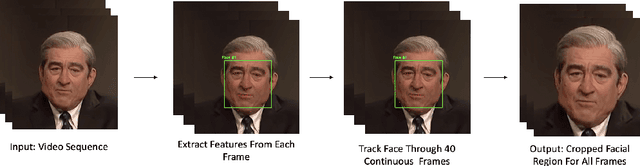
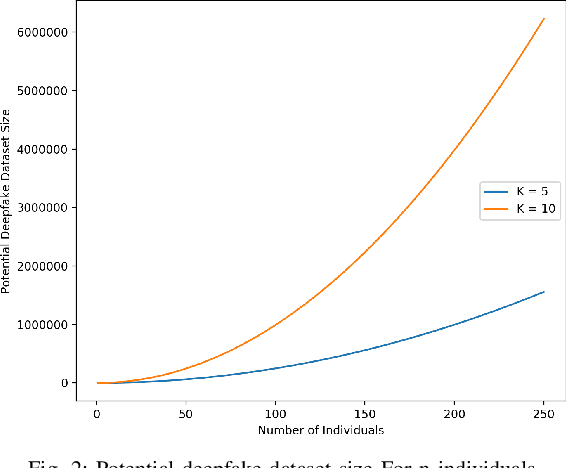

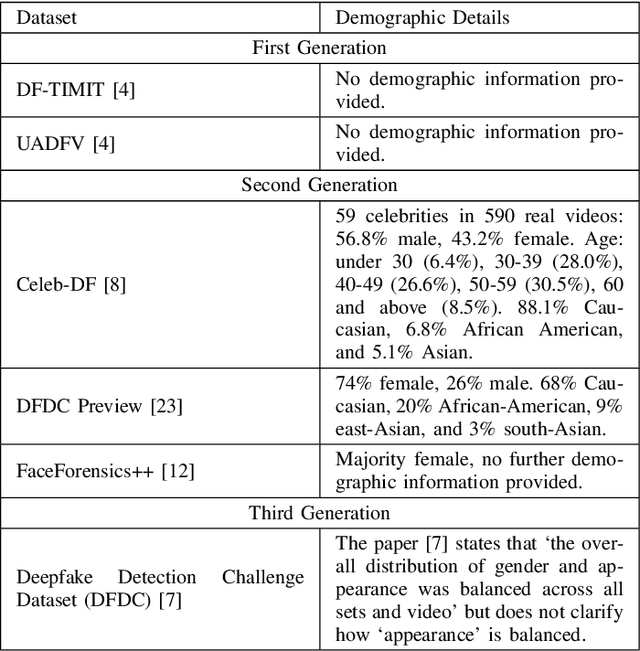
Deepfakes are a form of synthetic image generation used to generate fake videos of individuals for malicious purposes. The resulting videos may be used to spread misinformation, reduce trust in media, or as a form of blackmail. These threats necessitate automated methods of deepfake video detection. This paper investigates whether temporal information can improve the deepfake detection performance of deep learning models. To investigate this, we propose a framework that classifies new and existing approaches by their defining characteristics. These are the types of feature extraction: automatic or manual, and the temporal relationship between frames: dependent or independent. We apply this framework to investigate the effect of temporal dependency on a model's deepfake detection performance. We find that temporal dependency produces a statistically significant (p < 0.05) increase in performance in classifying real images for the model using automatic feature selection, demonstrating that spatio-temporal information can increase the performance of deepfake video detection models.