 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DKU-DUKEECE System for the Manipulation Region Location Task of ADD 2023
Paper and Code

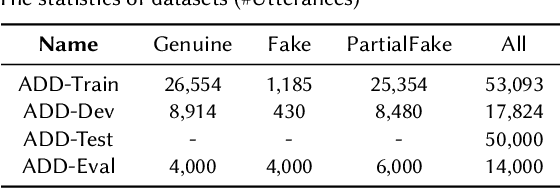

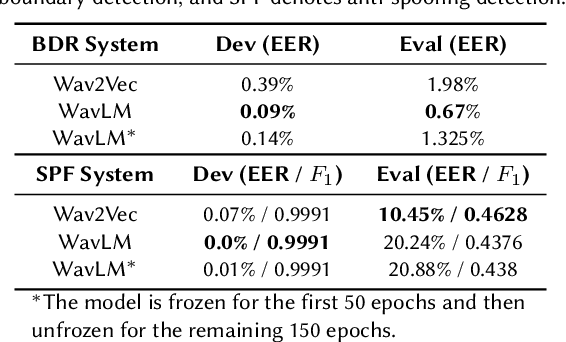
This paper introduces our system designed for Track 2, which focuses on locating manipulated regions, in the second Audio Deepfake Detection Challenge (ADD 2023). Our approach involves the utilization of multiple detection systems to identify splicing regions and determine their authenticity. Specifically, we train and integrate two frame-level systems: one for boundary detection and the other for deepfake detection. Additionally, we employ a third VAE model trained exclusively on genuine data to determine the authenticity of a given audio clip. Through the fusion of these three systems, our top-performing solution for the ADD challenge achieves an impressive 82.23% sentence accuracy and an F1 score of 60.66%. This results in a final ADD score of 0.6713, securing the first rank in Track 2 of ADD 2023.