 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cursive Transformer
Paper and Code
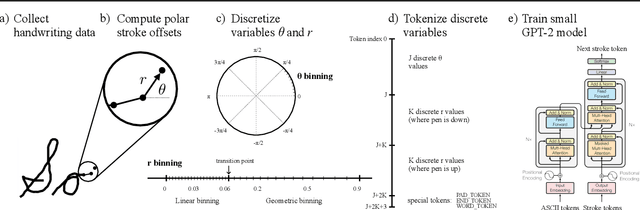
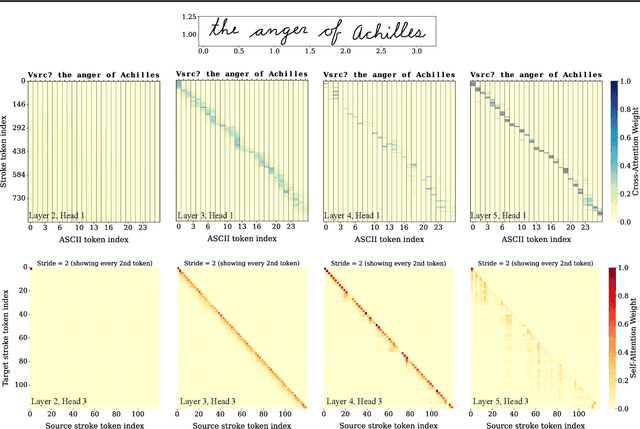

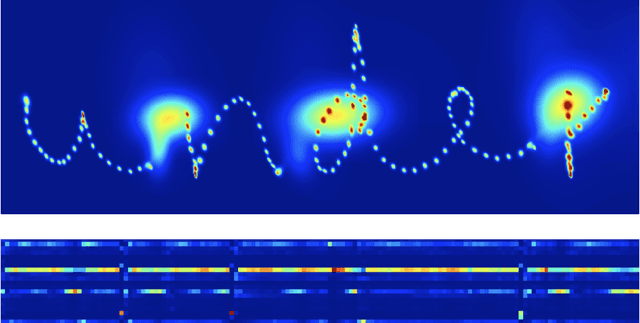
Transformers trained on tokenized text, audio, and images can generate high-quality autoregressive samples. But handwriting data, represented as sequences of pen coordinates, remains underexplored. We introduce a novel tokenization scheme that converts pen stroke offsets to polar coordinates, discretizes them into bins, and then turns them into sequences of tokens with which to train a standard GPT model. This allows us to capture complex stroke distributions without using any specialized architectures (eg. the mixture density network or the self-advancing ASCII attention head from Graves 2014). With just 3,500 handwritten words and a few simple data augmentations, we are able to train a model that can generate realistic cursive handwriting. Our approach is simpler and more performant than previous RNN-based methods.