Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe algorithm of noisy k-means
Paper and Code
Aug 15, 2013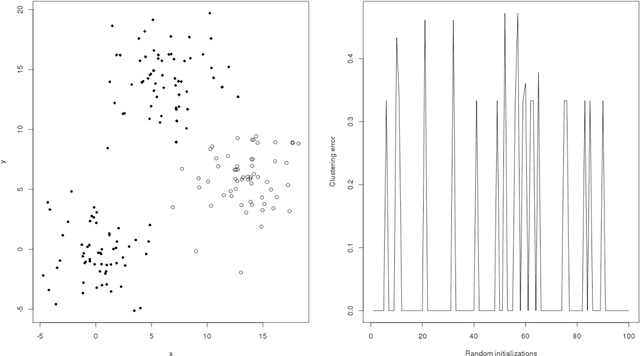
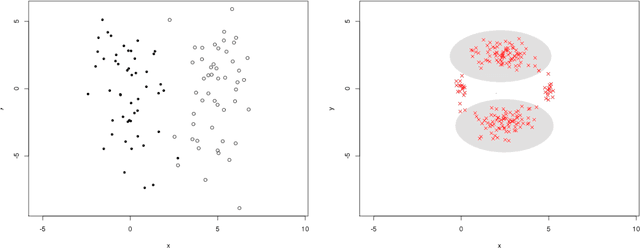
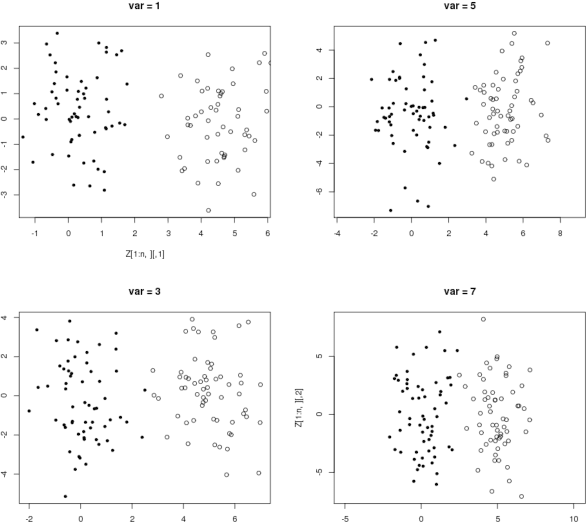
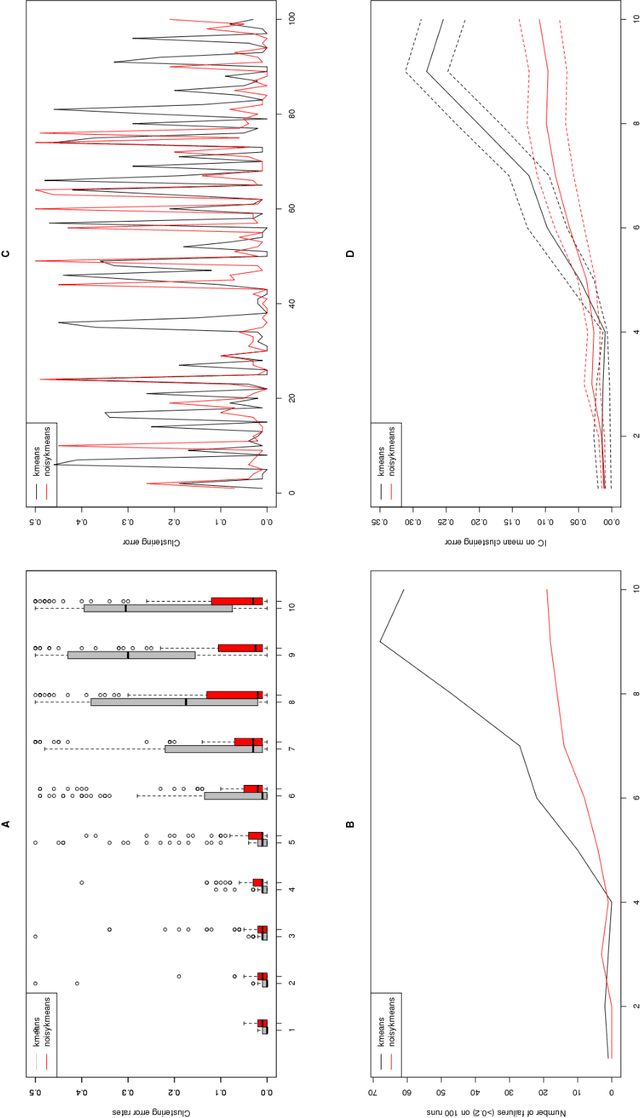
In this note, we introduce a new algorithm to deal with finite dimensional clustering with errors in variables. The design of this algorithm is based on recent theoretical advances (see Loustau (2013a,b)) in statistical learning with errors in variables. As the previous mentioned papers, the algorithm mixes different tools from the inverse problem literature and the machine learning community. Coarsely, it is based on a two-step procedure: (1) a deconvolution step to deal with noisy inputs and (2) Newton's iterations as the popular k-means.
View paper on